What Is an Enterprise Service Mesh?
A good place to begin understanding Tetrate Service Bridge (TSB) is with the following statement, or partial definition

A good place to begin understanding Tetrate Service Bridge (TSB) is with the following statement, or partial definition:
TSB is an enterprise service mesh.
The above statement begs two important questions:
- What is a service mesh?
- How is an enterprise service mesh different from, say, just a plain-old open-source service mesh, such as Istio?
In this article I’m going to assume that you, the reader, have some familiarity with service meshes, that you’ve perhaps looked at Istio, maybe even experimented with it, who knows perhaps you’re already running it in production!That is, this article will focus on the latter question: What is an enterprise service mesh? What distinguishes an enterprise mesh from, say, Istio?
What Is an Enterprise?
It’s important to begin by asking: what are enterprises’ needs with respect to the information systems that support their ability to serve their customers?
Presumably, enterprises need apps with all of the characteristics that we today associate with the term cloud-native: highly available, scalable, resilient, secure, observable, and portable (as in: moveable from one cloud provider to another).
But we can go further. We can assume that an “enterprise” is large in terms of the number of employees, and that it consists of many teams who work together towards a common goal, and mission.
We can assume such an enterprise has a relatively sizable need for infrastructure, they probably operate more than just one or two Kubernetes clusters.
From the above analysis, we can perhaps get to our first “take” at what constitutes an enterprise service mesh:
- Multi-cluster: it supports workloads running on many Kubernetes clusters.
- Mesh expansion: it supports VM workloads in addition to Kubernetes workloads.
- Multi-tenant: It supports, and properly segregates the efforts of many teams.
- Enterprise-grade: it comes with “batteries included,” and provides opinionated integrations with a carefully selected set of “high-grade” components.
- Support: It comes with enterprise support.
With these general criteria in mind, let us proceed to evaluate Istio against them. The Istio documentation contains a page titled “Deployment Models” that similarly discusses the deployment of Istio along four different dimensions, one vs many: clusters, networks, control planes, and meshes, which I highly recommend you read.
Multi-Cluster
The Istio service mesh supports the installation of a mesh that spans multiple Kubernetes clusters. The Istio reference documentation dedicates an entire section to the topic of Multi-cluster installation.Here is Istio’s reference illustration of the primary-remote deployment model:
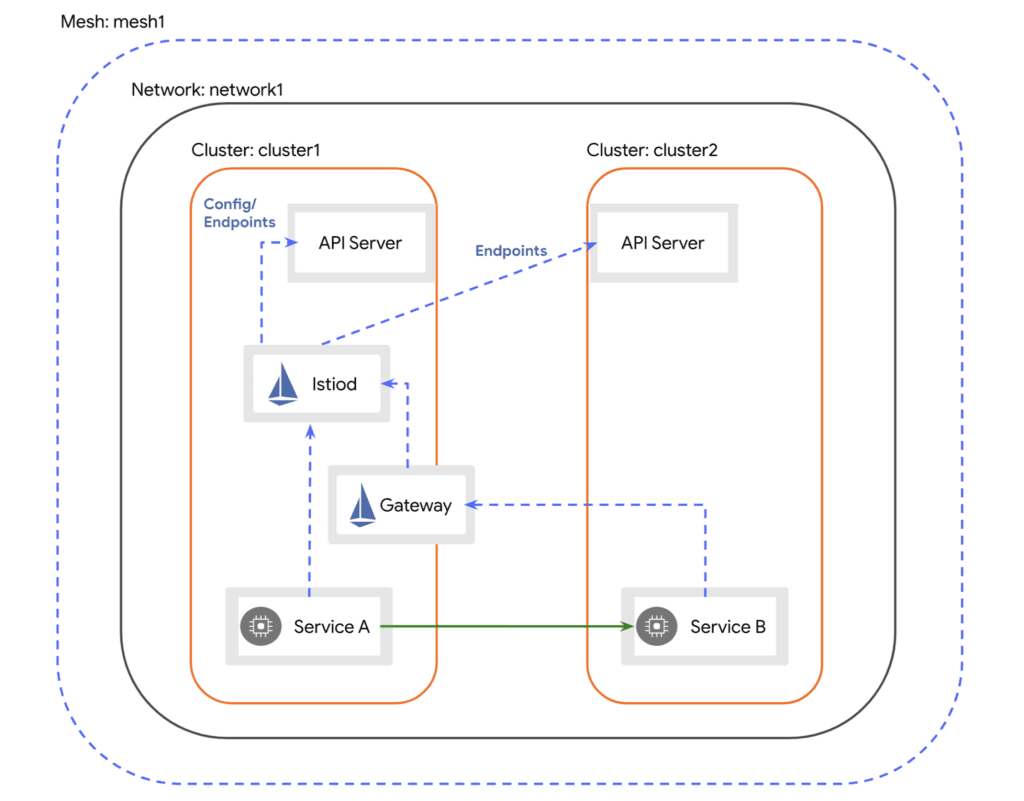
This illustration does a great job of explaining how a mesh involving workloads spanning two Kubernetes clusters would work. In the illustration, we see the Istio control plane, Istiod, residing on one of the two clusters, dubbed the primary cluster. The other cluster is fittingly labeled the remote cluster. We see workloads on both clusters: Service A in the primary and Service B in the secondary. Istiod has no difficulty injecting sidecars and programming them on the primary cluster. But for the same magic to function on the remote cluster we must:
- Provide a way for Istiod to receive events from the Kubernetes API service running on the remote cluster, so that it can discover the workloads running there.
- Install Istio components, such as the sidecar injector, on the remote cluster.
- Provide a way for Istiod to communicate with and program the remote sidecars; that is the role of the east-west gateway that is depicted in the illustration.
There are variations on that general design, depending for example, on whether the two clusters reside on the same network, or whether we want to achieve some measure of high availability with respect to the Istio control plane (multi-primary).
I find this design elegant: it’s a simple and logical extension of Istio to multiple clusters. And this works, though it may not take into account specific security considerations.
And yet, I am going to maintain that, fundamentally, the idea of putting an Istio control plane in charge of an increasing number of workloads, residing on an increasing number of Kubernetes clusters, does not scale.
At some point, something else, some higher level abstraction is required to manage, or solve this problem.
This subject came up recently at the Istio Day “Ask me anything” panel at Kubecon 2023 where Mitch Connors and others on the panel made some very important points:
- That Istio was designed and built primarily to manage a fleet of Envoy proxies in a single Kubernetes cluster, and that
- Something else needs to come along to solve the problem of managing a fleet of Istio control planes across dozens, even hundreds of Kubernetes clusters.
In that discussion, in those words, is the idea of a design for a multi-cluster mesh solution whereby one-to-one mapping between Istio control planes and Kubernetes clusters is maintained, while some other higher level concept can be built to deal with the problems of managing all of those Istio control planes.
Back to the Enterprise
A useful thought experiment is imagining an enterprise adopting Istio as their service mesh, and asking ourselves, or perhaps anticipating, what challenges would teams inside that enterprise face?
Imagine one app team deciding to adopt Istio service mesh. They stand up a cluster, install Istio, and deploy their workloads, configure the mesh. Hopefully the team is a cross-functional team with the operator know-how to manage their mesh residing within the team. Or maybe company policy requires that separate operations or platform teams be involved. The organization likely has an interest in developing a repeatable process for managing the lifecycle of Istio, and applying a uniform process for onboarding additional teams at a later time.
Separately is the question of multi-tenancy: how do we isolate the workloads of one team from others? One cluster per team could provide this isolation benefit, but is it too broad?
Another question we could ask is: what are the availability requirements of the application (or applications) managed by that team? If they require failover to another region, a single cluster might not be sufficient.
The main issue I see is the cost of managing the mesh platform is a function of the number of clusters we wish to manage. It is a recurring cost. The cost of installing, patching, and upgrading Istio, the cost of configuring or integrating observability with the enterprise observability platform, for example.
Second, there is the issue of heterogeneity: multiple independent teams each managing their own clusters and meshes will likely produce a heterogeneous environment, where things are managed differently by different individuals. Different clusters might be running different versions of Istio, upgrade schedules, and processes would be different.
Then there is the ratio of operators to development teams. Some years ago I used to work at a company by the name of Pivotal, whose chief product was Pivotal Cloud Foundry, a cloud platform that boasted a high developer to operator ratio.
The main challenges I envision are: duplication of effort, increased operational burden, and lack of central control.
Platform team in that enterprise would at some point seek to construct a single enterprise platform, managed by a single operations team, that provides service mesh “as a service” to all app teams. This platform would provide a coherent way to manage large infrastructure efficiently, spanning multiple clusters, across multiple cloud providers.
The dilemma at the enterprise of course is: How much do we invest in building such a platform? What are the risks? What are the costs? How long will it take?
TSB is a service mesh management platform, where Istio is a building block of a larger architecture.
TSB provides what we call a “management plane” that manages a fleet of Istio control planes, one per Kubernetes cluster. TSB manages the full lifecycle of an Istio instance in each of those clusters. The responsibility of a single Istio control plane is scoped to the cluster it resides on.
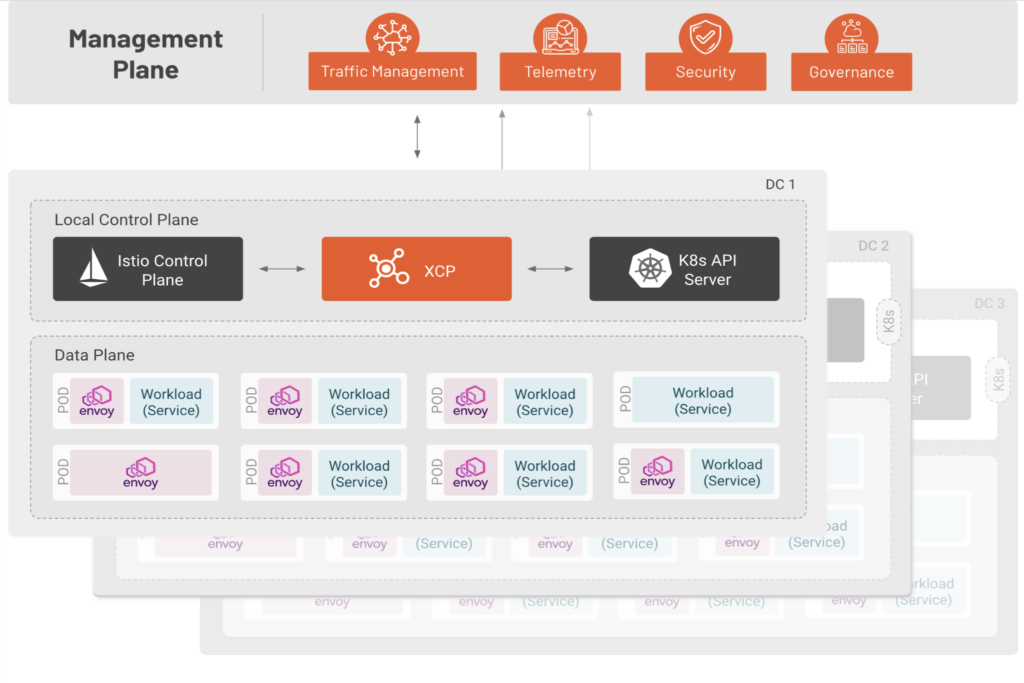
With TSB, one of the main activities of a platform team is to onboard clusters. When a cluster is onboarded, it is brought under the management of TSB.
Workloads running on those clusters are surfaced to the management plane, which has a view of all services across the larger infrastructure. This infrastructure can span multiple cloud providers. This gives us cross-cluster service discovery.
TSB collects and surfaces telemetry to the management plane. So observability across all of those clusters and workloads is consolidated in one place. This gives us global visibility.
In the reverse direction, mesh configurations (security policies, traffic policies, etc.) are applied to the TSB API server residing on the management plane, and pushed, or distributed to all applicable clusters. This enables centralized policy over all aspects of the mesh, across all that infrastructure.
Multi-Tenancy and the Concept of the Workspace
TSB has multi-tenancy built in. One specific concept in TSB that I find remarkable in its simplicity and its value, is the notion of a Workspace: a logical swath of infrastructure described as a list of cluster-namespace pairs. For example, given clusters c1 and c2, and Kubernetes namespaces app1 and app2 in each cluster, we can define a Workspace spanning the namespaces app1 across both clusters like so: [c1/app1, c2/app1].
This scope designation allows an app team to have a footprint that spans multiple clusters, and that is isolated from other workloads belonging to other teams.
This means that applications can be deployed redundantly across multiple clusters, regions, and cloud providers, giving applications immunity over many failure scenarios.
There is more to multi-tenancy in TSB, including the built-in notion of a tenant, and a permissions model that gives different personas in the organization jurisdiction over their aspect of the system, be it ingress configuration, security, or traffic management.
Multi-tenancy is multi-faceted. It can be broken down along different axes:
- Consumption: Isolating workloads that belong to different applications or teams.
- Traffic: Isolating routing of traffic for a certain application or team, via dedicated gateways.
- Administration and configuration: Isolating configuration resources to a specific application or tenant.
TSB supports all three.
Gateways
TSB leverages gateways in different ways to support routing requests to workloads in a highly-available way. Edge gateways are easily deployed at the edge and allow failover to another cluster if the original cluster becomes unavailable. East-west gateways allow service-to-service calls to failover from one cluster to another when workloads turn out to be unavailable in the local cluster.
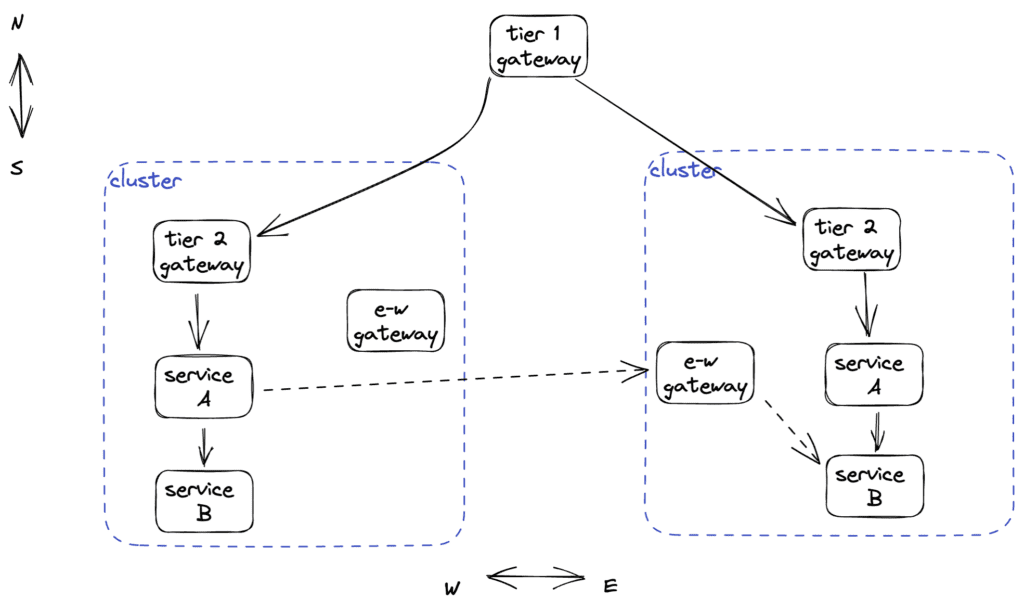
Locality-Aware Routing
When microservices within an application need to communicate, workloads that are nearest (within the same locality) the caller will be given preference.
If no workloads are available locally, routing falls back to workloads residing in clusters, availability zones, and regions that are further away.Istio lays the groundwork for this locality-aware routing feature. TSB refines and operationalizes it in the context of a running multi-cluster service mesh (see here).
TSB Implies Istio
Because Istio is the main building block in TSB, all of the features and capabilities of Istio are present in TSB. TSB provides a way to extend and scale that goodness across the enterprise, and in a coherent way.
One of the fundamental problems in the enterprise is the ability to uniformly control and manage workloads across large infrastructure footprint. We want a single platform team to be able to support multiple application teams, and for each team to be able to do its work in isolation from other teams. TSB provides those capabilities.
An Analogy
The relationship that TSB has with Istio is similar to the relationship Istio has with Envoy.
Imagine managing a small application consisting of two to three services. Perhaps we can manually install two to three Envoys and manually configure them. As the system grows to dozens, and hundreds of services, manually managing the Envoy proxies becomes untenable. And so we introduce a control plane, we call it Istio, that allows us to centralize configuration in one place. Istio generates and distributes those configurations to all the Envoy proxies.
The above paragraph can be revised by replacing all references of Istio and Envoy with TSB and Istio respectively:
Imagine managing a small system consisting of two to three Kubernetes clusters. Perhaps we can manually install two to three Istio control planes and manually configure them. As the system grows to dozens, and hundreds of clusters, manually managing the Istio control planes becomes untenable. And so we introduce a management plane, we call it TSB, that allows us to centralize configuration in one place. TSB generates and distributes those configurations to all the Istio control planes.
In a sense, TSB is a control plane for Istio.
Enterprise Grade
In the introduction to this article, I defined “enterprise-grade” as a product that “comes with batteries included”, one that provides opinionated integrations with a carefully selected set of “high-grade” components, ones that pass the test of scale.
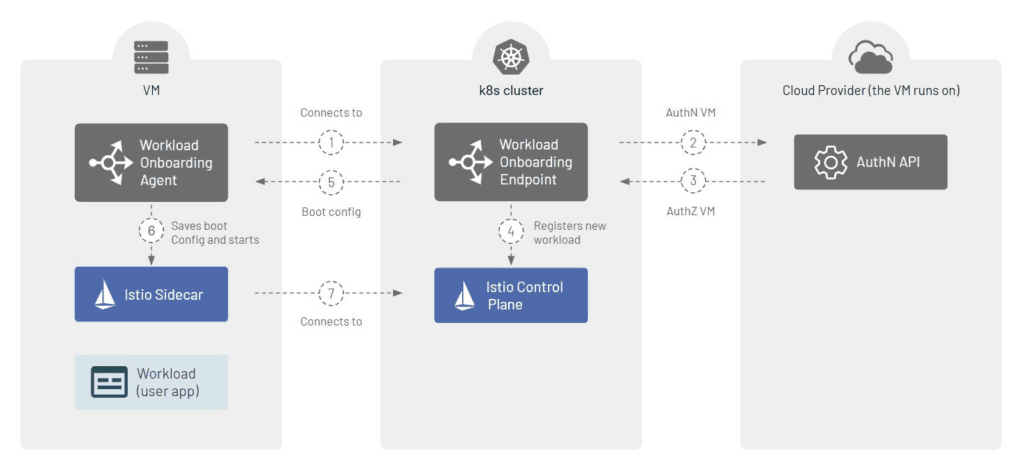
TSB is indeed an opinionated product. It integrates by default with Apache Skywalking, a high-grade observability solution that has proven itself at large cloud-scale organizations such as Alibaba and Baidu. As your TSB footprint grows to hundreds of clusters, Apache Skywalking will not have any difficulty doing its job supporting monitoring and observability of your workloads.Another case in point is how TSB addresses the problem of mesh expansion to virtual machines (VMs). In the enterprise, plenty of workloads continue to run on VMs. The basic capability of onboarding VMs is built-in to Istio (see here). TSB solves this problem at scale (see here). TSB provides components that allow a VM to automatically request to join the mesh via an onboarding endpoint, and integrations with cloud providers such as AWS to perform secure workload attestation. Once the workload has been vetted, TSB automates the remaining steps of registering the workload entry, and bootstrapping the Envoy sidecar on the VM.
Summary
We have come full circle. I hope that I have done my job and clearly answered the question:
How is an enterprise service mesh different from, say, just a plain-old open-source service mesh, such as Istio?
We looked at “enterprise service mesh” from the point of view of a mesh that:
- Runs atop a large infrastructure footprint comprising hundreds of Kubernetes clusters,
- Supports multi-tenancy out of the box, where that infrastructure footprint can be parceled out across many application teams,
- Is designed and implemented to be enterprise-grade, and finally,
- Comes with enterprise support.
As enterprises evaluate and adopt this exciting technology that we call “service mesh” for its capabilities along the axes of high availability, resilience, security, traffic management, and observability, it’s important to remember that these capabilities need to be unlocked enterprise-wide.










