Service Mesh Deployment Best Practices for Security and High Availability
This is the second in a series of service mesh best practices articles excerpted from Tetrate’s forthcoming book, Istio in Production, by Tetrate foun

This is the second in a series of service mesh best practices articles excerpted from Tetrate’s forthcoming book, Istio in Production_, by Tetrate founding engineer Zack Butcher._
There are a few moving pieces when it comes to a service mesh deployment in a real infrastructure across many clusters. The primary pieces we want to highlight here are how control planes should be deployed near applications, how ingresses should be deployed to facilitate safety and agility, how to facilitate cross-cluster load balancing using Envoy, and what certificates should look like inside the mesh.
Align Service Mesh Control Planes with Failure Domains
Recommendation: deploy loosely-coupled control planes around failure domains for high availability.
Building high availability systems can be challenging and, often, expensive. One of the tried-and-true techniques we know is to build around failure domains. A failure domain is the section of your infrastructure that is affected when a critical system fails. The fundamental way we build reliable systems is to group the sets of failure domains the system straddles into replicated silos as multiple, independent instances. The overall reliability of the resulting system depends on how independent we can make the silos. In practice there is always some interdependence, and minimizing it is always a trade off of cost against availability.
One of the easiest ways to create isolated silos without coupled failure domains is to run independent replicas of critical services in each silo. We could say that these replicas are local to the silo—they share the same failure domains. In a cloud-native architecture, the Kubernetes clusters form the most natural silo boundary. Istio is a critical service, so we run an instance of the Istio control plane in every application cluster. In other words, we deploy Istio so its failure domains align with those of your applications.
Further, we make sure the Istio control plane instances are loosely coupled and don’t need to communicate directly with other clusters, minimizing communication external to their silo. See the multi-cluster section below for detail on how to achieve this.
Isolate Traffic Per Application with Application Ingress Gateways
Recommendation: start with a gateway for each application or application team—an Application Ingress Gateway—to help mitigate shared outages. As you gain operational experience, merge application ingress into shared gateways over time to optimize cost.
While Istio ships with the shared istio-ingressgateway by default, we do not recommend using a shared gateway. Most teams adopting the mesh need time to build the review practices and operationalization required to implement a shared gateway model without a risk of shared outages. Especially early in your Istio implementation, we recommend an Envoy gateway deployment per team. We call these Application Ingress Gateways. As you gain operational experience, you can begin to merge together applications onto shared gateways as a cost optimization.
A shortcut to achieving per-team isolation with a shared gateway model is to assign a separate hostname to each team. Teams isolated by hostname can more safely configure a shared gateway instance. However, other shared-fate outage risks remain, like misconfiguration of the ingress proxy deployment, noisy neighbors consuming resources and increasing latency for all applications, and so on. In our experience, a gateway-per-team approach results in the fastest impact with least opportunity for failure, and comes at a relatively small cost overall.
The end state we expect in a mature deployment is an 80-20 split: most applications will receive traffic via a shared gateway, while a small set of highly critical or sensitive applications will keep dedicated gateways.
Distribute Ingress Traffic across Multiple Clusters with Application Edge Gateways
Recommendation: use an Application Edge Gateway to provide a single address for clients to consume and to distribute traffic to Application Ingress Gateways across multiple clusters.
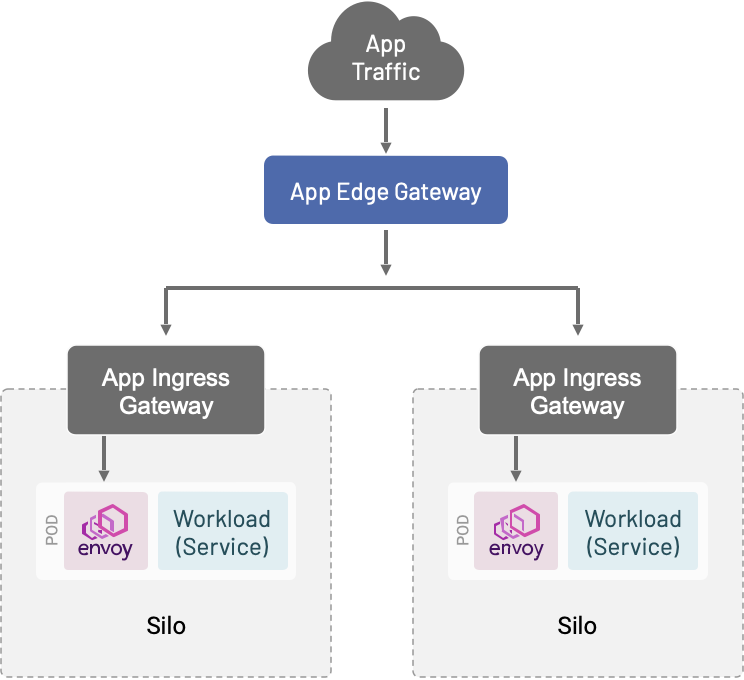
We often see the need from customers to distribute ingress traffic across several clusters. For example, they may want to enable blue/green infrastructure upgrades, to facilitate cross-region failover, or to implement the strangler pattern by migrating traffic from monoliths to microservices using Envoy’s L7 capabilities. We call these Application Edge Gateways.
To enable this use case, we will deploy Envoy—either in a dedicated Kubernetes cluster or as a set of VMs—to receive external traffic. These Envoy instances will forward traffic to your applications by way of their Kubernetes ingress or VM VIP. This works in tandem with an ingress-per-team approach: the multi-cluster gateway presents a single address for clients to consume, fronting as many application gateways and clusters as your infrastructure needs.
While this gateway does present a shared failure domain, its configuration is far simpler than the configuration of each application ingress gateway. Therefore, it’s easier to operationalize and safer to run as shared infrastructure. A shared application edge gateway with an application ingress gateway for each cluster is a powerful and flexible model for deploying and operating applications on the mesh that also enables easier operation of the underlying infrastructure.
Recommendations for Certificates and Public Key Infrastructure (PKI)
Recommendation: create an intermediate signing certificate for mesh mTLS from your existing corporate root.
Istio uses regular X.509 certificates for identity and to enable encryption in transit in the mesh. We recommend creating a mesh intermediate signing certificate for all mesh mTLS out of your existing corporate root. If you have a root per environment, create a mesh intermediate signing certificate per environment. Use that mesh intermediate issuing certificate to create a signing certificate per Istio installation. We recommend creating a mesh intermediate signing certificate so that the mesh’s entire PKI in any particular environment is a tree which can be invalidated together if the need arises. The cost is a little extra certificate management, requiring some care in managing the lifetimes of the mesh intermediate signing certificate compared to the control plane signing certificates.
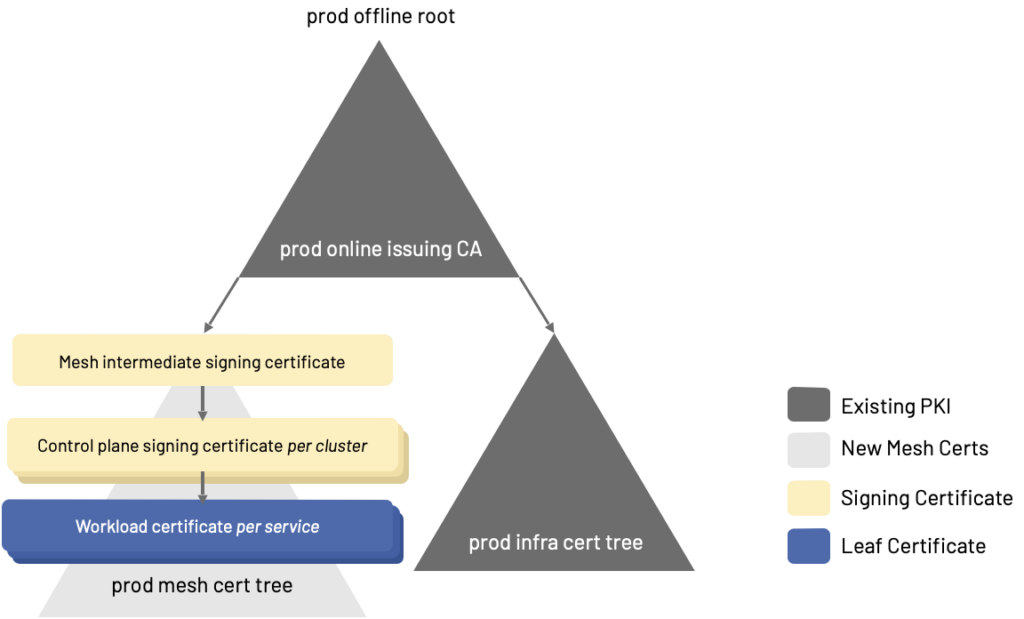
Istio watches the filesystem and will reload its signing certificate when it detects a change in the file. Therefore, as long as you have an approved mechanism to load secrets into the istiod pod’s filesystem—like cert-manager, Vault’s init-agent or sidecar, or just plain old Kubernetes secrets stored in an encrypted etcd—it should be easy to integrate Istio into your PKI. Rotation of the control plane signing certificate should be automated by your PKI.
Istio uses well-known cryptographic libraries: Istio’s internal CA uses Golang’s cryptographic suite, and Envoy (sidecar and ingress) uses BoringSSL for certificate validation and encryption in transit. FIPS-verified builds of both control plane and data plane are also available as part of Tetrate Istio Subscription via Tetrate’s open source Istio distribution, Tetrate Istio Distro, so all of the X.509 constraints you might expect (basic constraints like CA and depth, naming constraints, policy constraints, and so on) are supported and enforced out of the box.
Use Aggressively Short-Lived Workload Certificates for Easy Revocation
Recommendation: use Istio to automate certificate management so that it’s practical to set aggressively short workload certificate TTLs, keeping certificate revocation lists (CRLs) short and manageable.
The biggest challenge in PKI after certificate issuance and rotation—which Istio automates for you—is certificate revocation. Certificate revocation is implemented with a certificate revocation list, and it’s typical for CRLs to have an enforcement SLA of 24 hours: a certificate added to the list may be accepted by the infrastructure as valid for up to 24 hours after revocation. Further, since a revoked certificate must remain on the list for its entire lifetime (TTL), revocation lists can grow large and unwieldy.
A better solution, offered by Istio, is to automate certificate management so that it’s practical to set aggressively short workload certificate TTLs. By default, Istio ships with a workload certificate TTL of 24 hours. This is short enough that most security organizations can choose to let compromised certificates expire, rather than revoke them explicitly. And, when you do add a certificate to the CRL, it only needs to stay there for a very short time (since we don’t need to keep expired certs on the CRL). In this way, the mesh helps address the most painful PKI problems faced by most organizations: it issues and revokes short-lived certificates, which means that revocation lists can be kept short and manageable, when they’re needed at all.
Note: because the mesh uses mTLS certificates for identity, Istio configures Envoy to automatically drop established connections to force both client and server to re-authenticate each other when certificates are rotated by either party. This is a design decision in Istio’s implementation, and is typically hidden from applications by Istio’s resiliency capabilities: an automatic retry transparent to the application re-establishes the connection. Setting a shorter certificate TTL in the mesh forces these reconnects to happen more frequently. It’s worth noting that, infrequently, some applications that expect long-lived TCP connections can be disrupted by this behavior.
Further Certificate Recommendations
You should coordinate with your security team to establish appropriate constraints for certificates that your mesh issues. Some common constraints we recommend:
Certificate lifetime (TTL): Note that as long as certificates are issued out of the same root, Istio supports zero downtime rotation of the control plane signing certificates as well as workload certificates. We recommend the following certificate lifetimes for each level:
- 1-3 years for the mesh intermediate signing certificate
- 3 months for the control plane signing certificate
- 12-24 hours for workload certificates
Istio handles rotation of workload certificates automatically. A short TTL (less than 24 hours) on these certificates helps to time bound attacks with potentially stolen credentials and also reduces the need for CRLs. Control plane certificates should be rotated on a one-month offset to ensure a smooth transition – in other words, rotate the control plane signing certs 1 month before expiry on a 3 month TTL. Similarly, rotate the mesh intermediate signing certificate when it has between half to one-third of its lifetime remaining (3-4 months early for a one year TTL, 6-8 months early for a three year TTL).
Basic (CA and depth). The control plane signing certificates should only be able to issue leaf certificates: non-signing certificates for workload identification. Therefore the depth limit should be configured to prevent the control plane signing certificate from issuing any other signing certs.
The mesh intermediate signing certificate needs to create the control plane signing certs, therefore it should be configured with a depth to be able to create one level of signing certs below it and no more.
Name constraints. Istio-issued workload certificates do not populate the X.509 Subject Name (SN) field; mesh authentication relies on a SPIFFE identity carried as a Subject Alternate Name (SAN) field instead. Read the SPIFFE spec for information on validation and authentication works, as well as Istio’s documentation for how Istio encodes identity according to SPIFFE. Keep this in mind when writing Name Constraints for the mesh intermediate and control plane signing certificates.
Key usage. keyCertSign must be set for the mesh intermediate signing certificate as well as control plane signing certificates, but should be disabled for workload certificates. In other words, the mesh intermediate and control plane certs are signing certs and workload certs are not.
In line with SPIFFE’s recommendations, signing certificates should not be used for encryption in transit, and key usage should be configured to prevent it (via Encipherment constraints).
Extended Key Usage. While there are no specific requirements here, the SPIFFE X.509 SVID spec notes id-kp-serverAuth and id-kp-clientAuth should be configured for leaf (workload) certificates.
The SPIFFE spec also recommends a variety of certificate constraints, though most of those are captured above.
Parting Thoughts and What’s Next
We hope these best practices gleaned from years of experience helping our customers get the most out of service mesh will help facilitate your deployments. If you haven’t yet, take a look at the first post in the series on layering microservices security with traditional security to move fast, safely.
Next up: service mesh runtime configuration recommendations. In our next post, we’ll take review recommendations for:
- Naming conventions
- Global settings
- Traffic management
- Security
- Telemetry
If you’re new to service mesh and Kubernetes security, we have a bunch of free online courses available at Tetrate Academy that will quickly get you up to speed with Istio and Envoy.
If you’re looking for the surest way to get to production with Istio, check out Tetrate Istio Distribution (TID), Tetrate’s hardened, fully upstream Istio distribution, with FIPS-verified builds and support available. It’s a great way to get started with Istio knowing you have a trusted distribution to begin with, an expert team supporting you, and also have the option to get to FIPS compliance quickly if you need to.
As you add more apps to the mesh, you’ll need a unified way to manage those deployments and to coordinate the mandates of the different teams involved. That’s where Tetrate Service Bridge comes in. Learn more about how Tetrate Service Bridge makes service mesh more secure, manageable, and resilient here, or contact us for a quick demo.










