Performance Optimization for Istio
This article is part of a three-part series on Istio’s development, how to optimize Istio performance (this article), and Istio’s open source ecosystem

This article is part of a three-part series on Istio’s development, how to optimize Istio performance (this article), and Istio’s open source ecosystem and its future.
After Istio’s architecture stabilized in version 1.5 (March 2020), as mentioned in the previous article, the community’s main focus turned to optimizing performance. In the following sections, we’ll look at the different optimization methods that were considered by Istio and describe which approaches were adopted.
![]()
Tetrate offers an enterprise-ready, 100% upstream distribution of Istio, Tetrate Istio Subscription (TIS). TIS is the easiest way to get started with Istio for production use cases. TIS+, a hosted Day 2 operations solution for Istio, adds a global service registry, unified Istio metrics dashboard, and self-service troubleshooting.
Proxyless Mode
Proxyless mode is an experimental feature proposed in Istio 1.11. It envisions a service mesh based on gRPC and Istio, without a sidecar proxy. Using this pattern, we can add gRPC services directly to Istio without injecting an Envoy proxy into the pod. The figure below shows a comparison of sidecar mode and proxyless mode.
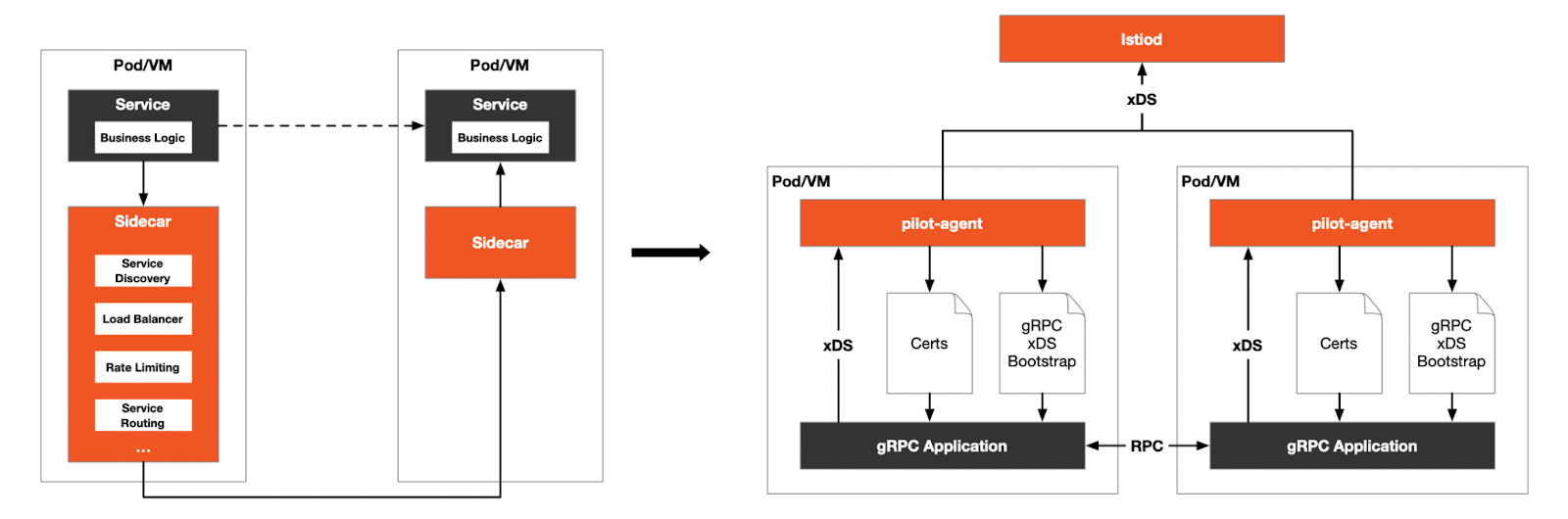
As we see from the figure above, although proxyless mode does not use a proxy for data plane communication, it still needs an agent for initialization and communication with the control plane. First, the Pilot agent generates a bootstrap file at startup, in the same way that it generates bootstrap files in the sidecar mode. This tells the gRPC library how to connect to istiod, where to find certificates for data plane communication, and what metadata to send to the control plane. Next, the Pilot agent acts as an xDS proxy, connecting and authenticating with istiod. Finally, the Pilot agent obtains and rotates the certificate used in the data plane communication. This behavior pattern is the same as the sidecar mode.
The essence of a service mesh is that it has a standardized method for inter-service communication, whether that is implemented in a sidecar model, a configuration center, or transparent traffic interception.
Some say that the proxyless model returns to the old approach of developing microservices based on an SDK, and the advantages of service meshes are lost. Can such an approach still be called service mesh? This is also a compromise on performance—if you mainly use gRPC to develop microservices, you only need to maintain gRPC versions in different languages; that is, you can manage microservices through the control plane. Whether these concerns are valid or not, the use of Envoy proxy as a sidecar has become the norm for Istio service mesh implementations.
## Optimizing Traffic Hijacking with eBPFEnvoy xDS has become the de facto standard for communication between services in the mesh.
Earlier, we referred to a diagram that shows the different iptables rules such as PREROUTING, ISTIO_INBOUND, ISTIO_IN_REDIRECT, OUTPUT, ISTIO_OUTPUT, and so on. The traffic is routed based on these routes before it reaches the application.
Suppose now that service A wants to call service B running in another pod on a different host. The figure below shows the request path through the network stack.
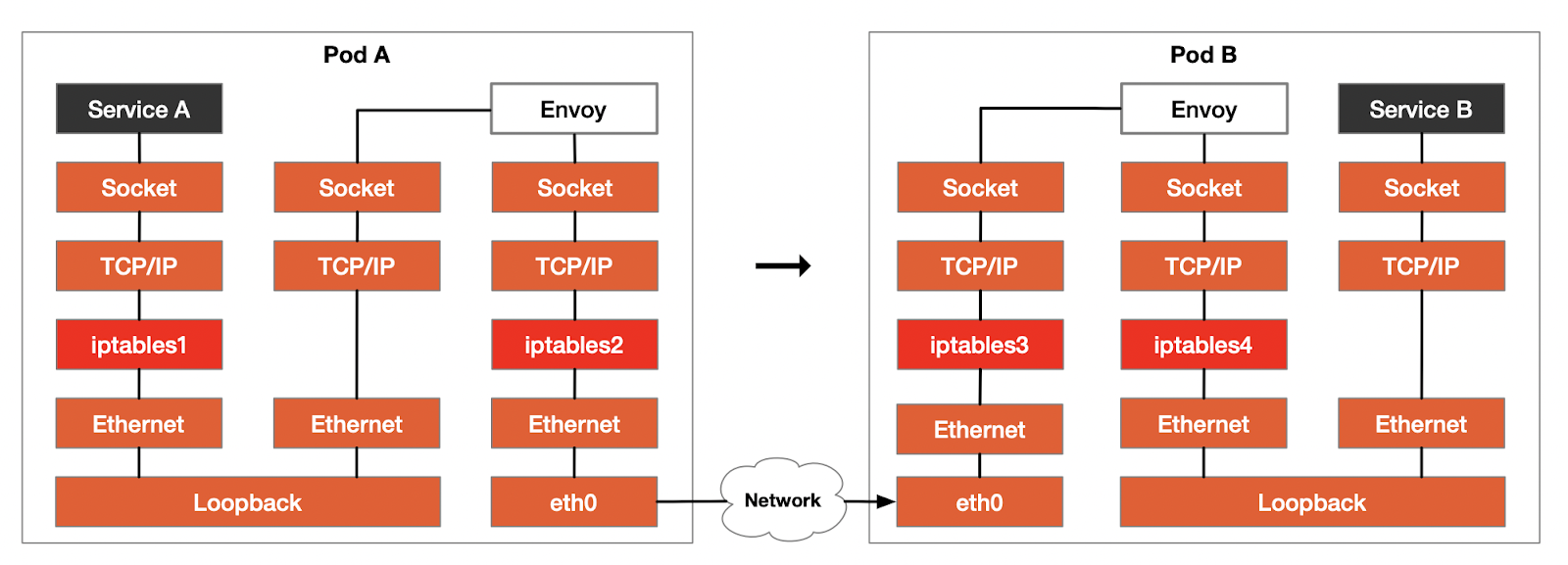
From the figure, we can see that there are four iptables passes in the whole calling process. Among them, the outbound (iptables2) from Envoy in Pod A and the inbound (iptables3) from eth0 in Pod B are unavoidable. So can the remaining two, iptables1 and iptables4 be optimized?
Would it be possible to shorten the network path by letting the two sockets communicate directly? This requires programming through eBPF such that:
- Service A’s traffic is sent directly to Envoy’s inbound socket.
- After Envoy in Pod B receives the inbound traffic, it has determined that the traffic is to be sent to the local service and directly connects the outbound socket to Service B.
The transparent traffic interception network path using eBPF mode is shown in the following figure.
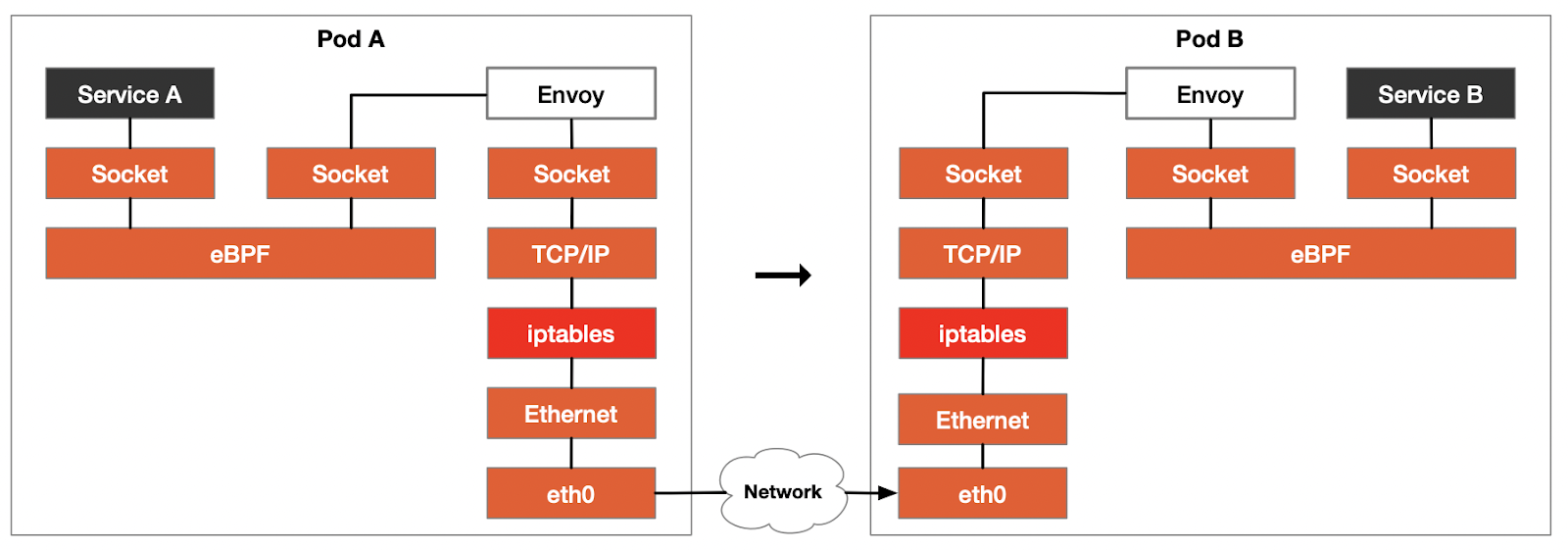
The network path is shorter if services A and B are on the same node.
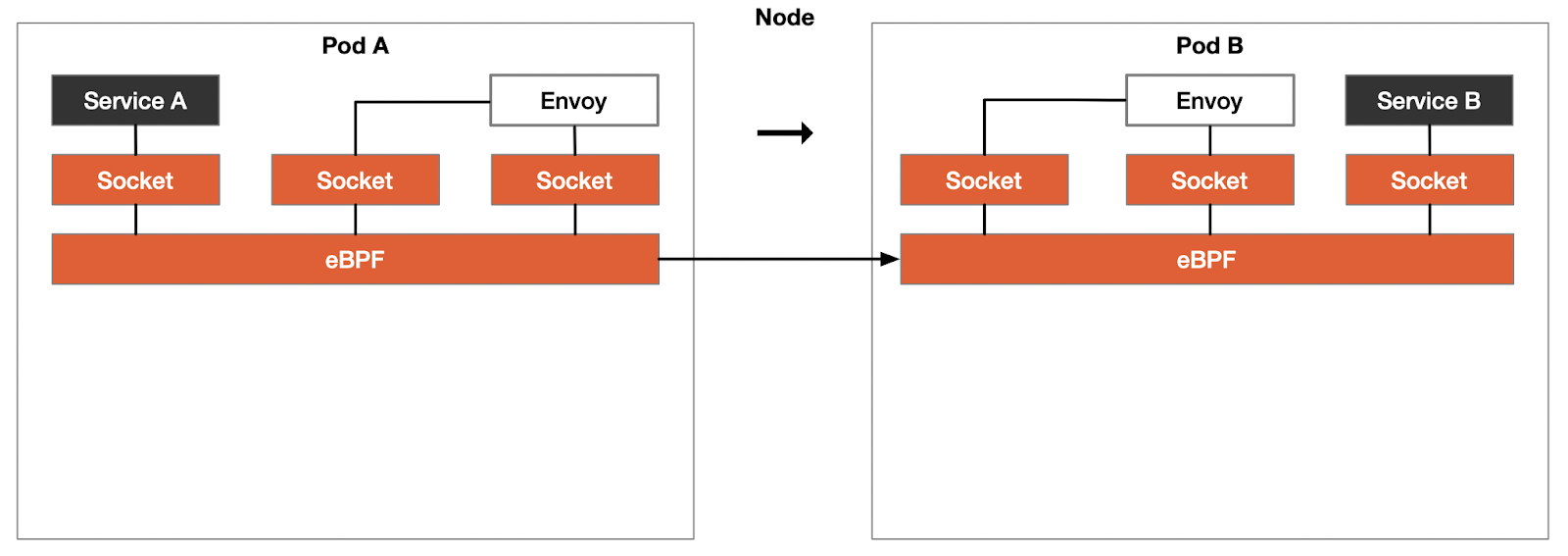
Access between services on the same node completely bypasses the TCP/IP stack and becomes direct access between sockets.
What Is eBPF?
As we’ve discussed elsewhere, eBPF is a framework that allows users to load and run custom programs within the operating system’s kernel. That is, with eBPF, you can extend and change the behavior of the kernel without directly modifying the kernel code.
After the eBPF program is loaded into the kernel, it must pass the verifier verification before it can run. The verifier can prevent the eBPF program from accessing beyond its authority, ensuring the kernel’s security.
eBPF programs are attached to kernel events and are triggered on entry or exit from a kernel function. In kernel space, eBPF programs must be written in a language that supports a compiler that generates eBPF byte code. Currently, you can write eBPF programs in C and Rust. Note that the eBPF program has compatibility issues with certain Linux versions.
Since the eBPF program can directly monitor and operate the Linux kernel, it has a view of the lowest level of the system. It can play a role in traffic management, observability, and security.
The open source project Merbridge uses eBPF to shorten the path of transparent traffic hijacking and optimize the performance of the service mesh. For details on the Merbridge implementation, you can refer to this Istio blog post. The eBPF functions used by Merbridge require a Linux kernel version of at least 5.7 (May 2020).
At first glance, eBPF seems to implement the functions of Istio at a lower level and may be able to eliminate the need for a sidecar. But eBPF also has many limitations that make it impossible to replace service meshes and sidecars in the foreseeable future. Removing the sidecar in favor of a proxy-per-host model would result in the following:
- The blast radius of a proxy failure is expanded to the entire node.
- Security becomes more complicated because too many certificates are stored on a single node. If the node is compromised, all certificates and keys are compromised as well.
- Traffic contention is increased between pods on the host.
Moreover, eBPF is mainly responsible for Layer 3/4 traffic and can run together with CNI, but it is not suitable to use eBPF for Layer 7 traffic.
Istio Control Plane Performance Optimization
We have just looked at potential data plane optimizations. In this section, we’ll look at how to optimize performance on the control plane side. You can think of a service mesh as a show, where the control plane is the director, and the data plane is all the actors. The director is not involved in the show but directs the actors. If the show’s plot is simple and the duration is very short, then each actor will be allocated very few scenes, and rehearsal will be very easy.
If it is a large-scale show, the number of actors is large, and the plot is very complicated. To rehearse the show well, one director may not be enough. They can’t direct so many actors, so we need multiple assistant directors (expanding the number of control plane instances). We also need to prepare lines and scripts for the actors. If actors can perform a series of lines and scenes in one shot (reducing the interruption of the data plane and pushing updates in batches), does that make the rehearsal more efficient?
From the above analogy, we can tease out the different aspects of the control plane that can be optimized:
- Reduce the size of the configuration that needs to be pushed.
- Batch-push proxy configuration.
- Scale out the control plane by adding more instances.
Reduce the Amount of Configuration That Needs to Be Pushed Out
The most straightforward way to optimize control plane performance is to reduce the scope and size of the proxy configurations to be pushed to the data plane. Assuming there is a workload A, it is possible to significantly reduce both the size of the configuration and the scope of workloads to be pushed by only pushing the proxy configuration related to A (i.e., the services that A depends on) as opposed to the configuration of all services in the mesh. The Sidecar resource can help us control which configuration gets sent. The following is an example of a sidecar configuration:
apiVersion: networking.istio.io/v1alpha3
kind: Sidecar
metadata:
name: default
namespace: us-west-1
spec:
workloadSelector:
labels:
app: app-a
egress:
- hosts:
- "us-west-1/*"Listing 1. istio-sidecar-resource.yaml
We can use the workloadSelector field to limit the scope of workloads that the sidecar configuration applies to. The egress field is used to determine the scope of services the workload should be aware of. The control plane will configure the selected workloads to only receive configuration on how to reach services in the us-west-1 namespace, instead of pushing configuration for all services in the mesh. The configuration size being pushed by the control plane inside of the service mesh reduces its memory and network usage.
Batch-Push Proxy Configurations
The process of pushing the proxy configuration from the control plane to the data plane is complex. The following figure shows the process:
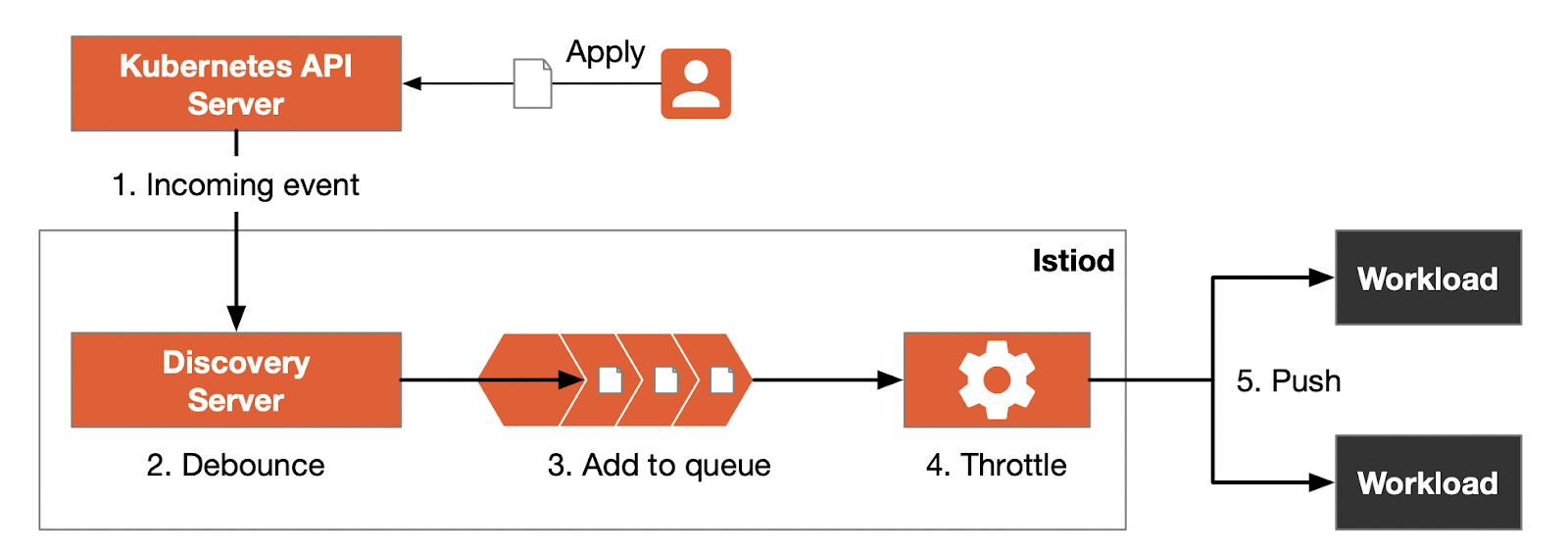
After an administrator configures the Istio mesh, the process of pushing proxy configuration is as follows:
- Events are created in the Kubernetes API server when an administrator modifies the mesh configuration in a Kubernetes cluster or when workloads are changed in Kubernetes.
- Istio’s DiscoveryServer components listen to these events and add them to the queue where the events get merged for a certain period of time. This process is called debouncing, and it prevents too-frequent updates to the data plane configuration.
- After the debouncing period, the events are pushed to the queue.
- To expedite the push progress, istiod limits the number of simultaneous push requests.
- Events are translated into Envoy configuration that gets pushed to the workloads.
From the above process, we can see that the key to optimizing the configuration push is the debounce period in Step 2 and the limit on the simultaneous pushes in Step 4. There are several environmental variables that can help us tweak the control plane pushes:
PILOT_DEBOUNCE_AFTER: The time after which the event will be added to the push queue.PILOT_DEBOUNCE_MAX: The maximum amount of time an event can debounce.PILOT_ENABLE_EDS_DEBOUNCE: Whether endpoint updates meet debounce rules, or whether they are given priority and move into the push queue immediately.PILOT_PUSH_THROTTLE: How many push requests are processed at once.
(Please refer to the Istio documentation for the default values and specific configuration of these environment variables.)
When setting these values, you can follow these principles:
- If control plane resources are idle, to speed up the propagation of configuration updates, you can:
- Shorten the debouncing period and increase the number of pushes.
- Increase the number of push requests processed simultaneously.
- If the control plane is saturated, to reduce performance bottlenecks, you can:
- Lengthen the debouncing cycle to reduce the number of pushes.
- Increase the number of push requests processed simultaneously.
The optimal solution will depend on your specific scenario. Make sure you refer to observability tools when making the optimizations.
Scale the Control Plane
If configuring the debounce batch processing and using the Sidecar resource don’t optimize the performance of the control plane, the last option is to scale out the control plane. This includes increasing the CPU and memory resources of a single istiod instance as well as increasing the number of instances. Whether to scale up or out depends on the situation:
- When the resource usage of an istiod instance is saturated, it is recommended that you increase its CPU and memory allocation. This is usually because there are too many resources in the service mesh (Istio’s custom resources, such as VirtualService, DestinationRule, etc.) that need to be processed.
- Then increase the number of instances of istiod so that the number of workloads to be managed by a single instance can be spread out.
Data Plane Performance Optimization
Apache SkyWalking can serve as an observability tool for Istio and can also help us analyze the performance of services in dynamic debugging and troubleshooting. The Apache SkyWalking Rover component uses eBPF technology to identify Istio’s key performance issues accurately.
We can increase Envoy’s throughput and optimize Istio’s performance with the following approaches:
- Disable Zipkin tracing or reducing the sampling rate.
- Simplify the access log format.
- Disable Envoy’s Access Log Service (ALS).
For data that shows the impact of the above optimizations on Envoy’s throughput, see Pinpoint Service Mesh Critical Performance Impact by using eBPF.
Envoy: the Service Mesh’s Leading Actor
We know that the service mesh is composed of the data plane and the control plane. From the list of service mesh open source projects we mentioned earlier, we can see that most of the projects are based on Envoy, while running their own control plane. If we continue with the previous analogy of Istio being a show, we can say that Envoy is the main actor and has a leading role.
The xDS protocol, invented for use by Envoy, has become a generic API for service meshes. The diagram below shows the architecture of Envoy:

The xDS API is what sets Envoy apart from other proxies. Its code and parsing mechanisms are intricate and difficult to expand. The following is a detailed overview of the different components in Istio mesh. From the figure, we can see that pilot-agent is the process that launches and manages the lifecycle of the Envoy proxy.

The role of the pilot-agent process is as follows:
- It’s the parent process in the container and it’s responsible for the lifecycle management of Envoy.
- It receives pushes from the control plane and configures the proxy and certificates.
- It collects Envoy statistics and aggregates sidecar statistics for Prometheus to collect.
- Using its own, built-in local DNS proxy, it resolves internal domain names of the cluster that cannot be resolved by Kubernetes DNS.
- It performs health checks for Envoy and the DNS proxy.
Based on the above roles of the pilot-agent, we can see that it is mainly used for interacting with istiod and being an intermediary between the control plane and the Envoy proxy.
Envoy Gateway: a Unified Service Mesh Gateway
In addition to the Kubernetes Services resource, the Ingress resource is the one that manages external access to services running inside the cluster. Using Ingress, we can expose services in the cluster and route traffic to services via HTTP hosts and URI paths. Compared to exposing services directly using the service resource, using the Ingress resource can reduce the network access point (PEP) of the cluster and reduce the risk of the cluster being attacked by the network; also, you only need one load balancer. The following figure shows the process of using Ingress to access services in the cluster.

![]()
Tetrate offers an enterprise-ready, 100% upstream distribution of Istio, Tetrate Istio Subscription (TIS). TIS is the easiest way to get started with Istio for production use cases. TIS+, a hosted Day 2 operations solution for Istio, adds a global service registry, unified Istio metrics dashboard, and self-service troubleshooting.
Before Kubernetes, API Gateway was widely used for edge routing. When referring to Istio, Istio’s custom Gateway resources are added, which makes accessing resources in the Istio service mesh one more option, as shown in the following figure.

Which option do we choose when exposing services in a single Istio service mesh? Do we pick NodePort, LoadBalancer, Istio Gateway, Kubernetes Ingress, or an API Gateway? How do clients access services within the mesh if it is a multi-cluster service mesh? In addition to working as a sidecar proxy in Istio, Kuma, and Consul Connect, Envoy Proxy can also be used standalone as an ingress gateway, as it is for Contour, Emissary, Hango and Gloo.
Because the Envoy community does not offer a control plane implementation, these projects use Envoy to implement service meshes and API Gateways, which results in a great deal of functional overlap, proprietary features, or a lack of community diversity.
In order to change the status quo, the Envoy community started the Envoy Gateway project. The project aims to combine the experience of existing Envoy-based, API Gateway-related projects. Some Envoy-specific extensions to the Kubernetes Gateway API lower the barrier to entry for Envoy users to use gateways. Because the Envoy Gateway still issues configuration to the Envoy proxy through xDS, you can also use it to manage gateways that support xDS, such as the Istio Gateway.
The gateways we have seen now are basically used as ingress gateways in a single cluster and can do nothing in multi-cluster and multi-mesh deployments. To deal with multiple clusters, we need to add another layer of gateways on top of Istio and a global control plane to route traffic between multiple clusters, as shown in the figure below.

A Brief Introduction to Two-Tier Gateways
The Tier-1 gateway (from now on referred to as T1) is located at the application edge and is used in a multi-cluster environment. The same application is hosted on different clusters at the same time, and the T1 gateway routes the application’s request traffic between these clusters.
The Tier-2 gateway (from now on referred to as T2) is located at the edge of a cluster and is used to route traffic to services within that cluster managed by the service mesh.
To manage multi-cluster service meshes, we add a layer on top called a global control plane. The global control plane and APIs work together and in addition to the Istio control planes in individual clusters. A single point of failure is prevented by clustering the T1 gateways. To learn more about two-tier gateways, refer to designing traffic flow via Tier-1 and Tier-2 ingress gateways.
This is an example of how a T1 gateway cloud can be configured:
apiVersion: gateway.tsb.tetrate.io/v2
kind: Tier1Gateway
metadata:
name: service1-tier1
group: demo-gw-group
organization: demo-org
tenant: demo-tenant
workspace: demo-ws
spec:
workloadSelector:
namespace: t1
labels:
app: gateway-t1
istio: ingressgateway
externalServers:
- name: service1
hostname: servicea.example.com
port: 80
tls: {}
clusters:
- name: cluster1
weight: 75
- name: cluster2
weight: 25Listing 2. t1-gateway-demo.yaml.
This configuration exposes the servicea.example.com service through the T1 gateway and forwards 75% of the traffic to cluster1 and 25% of the traffic to cluster2.
Tetrate’s commercial product, Tetrate Service Bridge (TSB), serves as a management plane for Istio. Among other capabilities, TSB is able to manage traffic, services, and security configurations across multiple clusters. To support this capability, a series of group APIs have been created. Look to the TSB documentation for details.
In the previous article, I reviewed the development of the Istio open source project and described how it relates to Envoy proxy and other components of the service mesh ecosystem. In this article, I showed how to optimize Istio performance. In the final article, I’ll describe Istio’s open source ecosystem and its future.








