
The Bottleneck Isn’t Your Models. It’s The Unproven Proxy In Front Of Them.
Uncontained Outages. Unattributed Spend. Ungoverned Sprawl.
Anthropic has a bad hour. Every on-call gets paged.
No failover, no load balancing across providers. One outage takes down agents across unrelated teams simultaneously.
The CFO asks which team spent $80K on tokens. No one can answer.
Token spend is attributed to a single API key. There’s no per-team, per-agent, or per-project breakdown to show for it.
A new developer needs model access. First, file a ticket.
No standardized on-ramp. Teams set up individual keys, individual billing, individual patterns. Leadership can’t see any of it.
An agent is misbehaving in production. Good luck finding out why.
Logs are scattered across provider dashboards. Reconstructing a multi-agent chain failure takes days, not minutes.
A Unified Gateway Between Your Agents and Every Model
100%
OpenAI-compatible, works with your existing code
<5 min
Typical time to first request through the gateway.
Provider, model, framework, or deployment model
0
Agent rewrites required to start routing through the gateway
Outcomes for Engineering Leaders.
Scaling AI Across Teams.
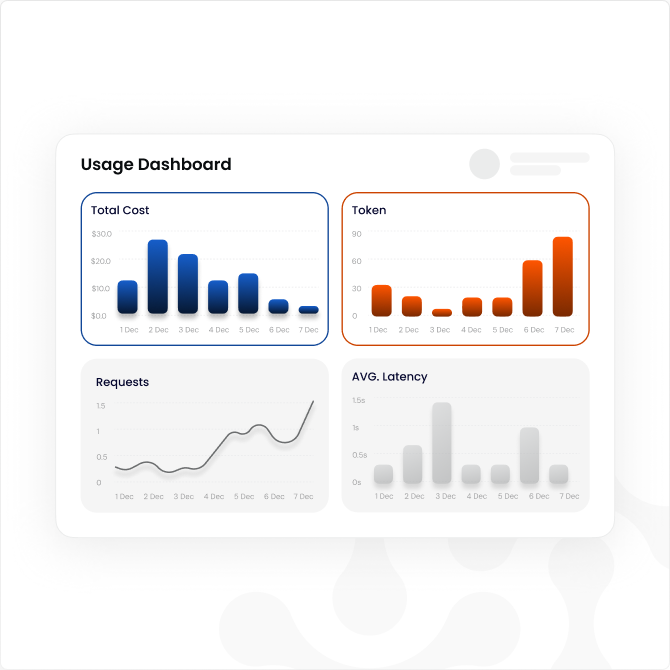
Which team spent $80K on tokens - and which team isn't using AI at all?
Per-team, per-agent, per-project token and cost attribution with inline budget enforcement. Flag the teams burning through budget and identify the ones not meeting adoption targets, from the same dashboard.
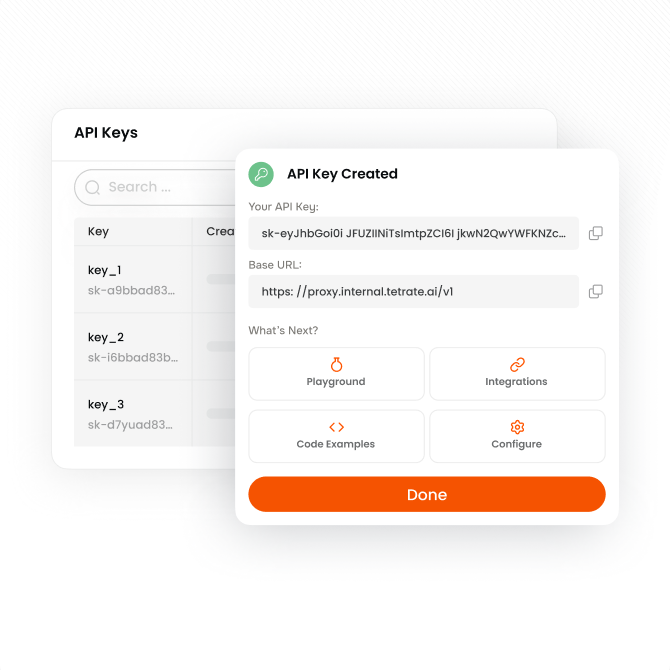
Getting developers onto AI is slow and painful.
A standardized, governed path to approved models and MCP servers. No ticket filing, no individual billing setup. Leaders set access profiles; developers inherit them.
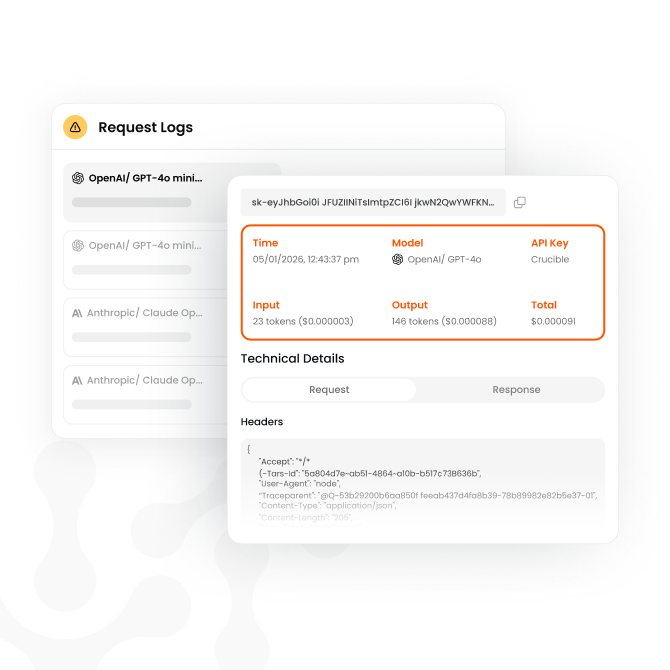
An agent is misbehaving. I can't tell why.
A unified log of every agent call across providers, frameworks, and teams. Get central visibility into multi-agent chains, find runaway token loops, cut debug time from days to minutes.
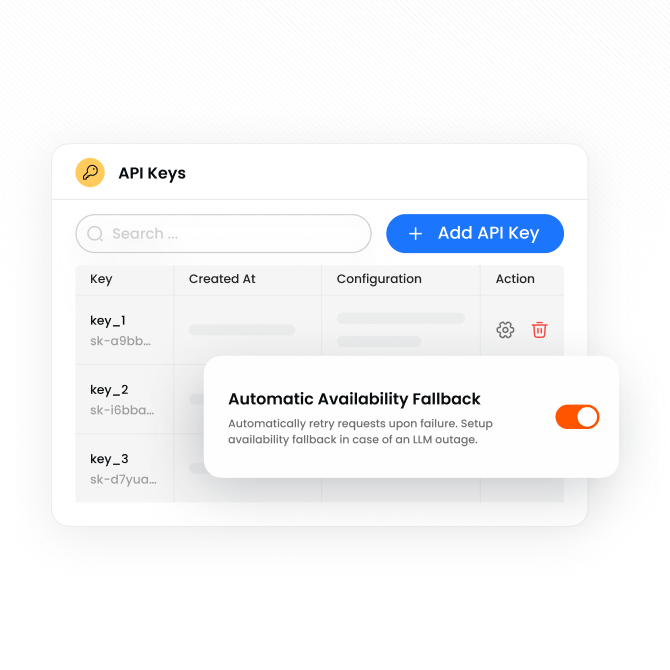
If Anthropic goes down, we all go down.
Automatic failover across internal or external model providers with policy-driven routing and model-version pinning. A provider outage is absorbed at the gateway, not distributed as an incident across every team.
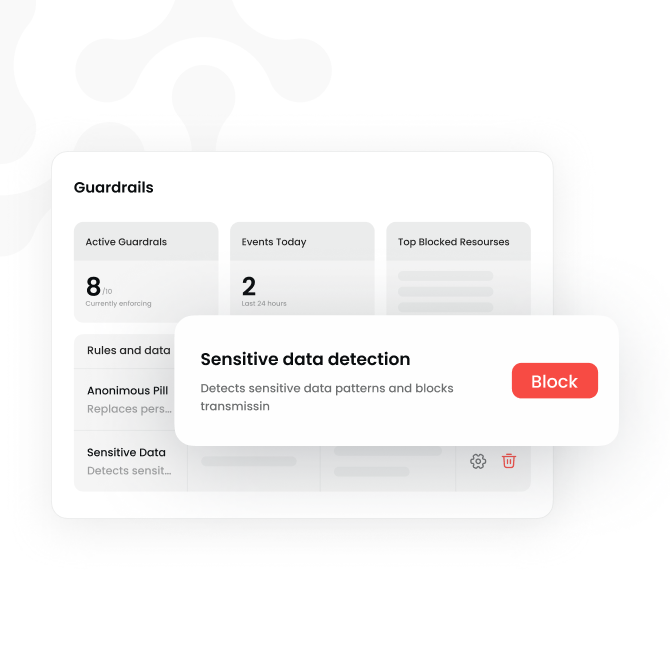
We need to show compliance. Policies are in a slide deck.
PII redaction, prompt filtering, and transaction blocking enforced in the request path, before damage is done. Audit evidence built in. Integrates with your existing guardrail providers.
Based on Envoy AI Gateway. Production-Hardened for Enterprise AI.
Tetrate built and runs Envoy at enterprise scale. Agent Router runs on the same distributed systems architecture, not a repackaged API proxy.
That matters when you're running agents across multiple teams, regions, and providers.
27.9K GitHub Stars
Envoy Proxy
1M+ User Events Per Second
Airbnb with Envoy
2M+ Requests Per Second
Lyft with Envoy
Billions API Requests Daily
Netflix with Envoy


Start Fast. Scale When You're Ready.
Agent Router Service
FOR DEVELOPERS
Everything you need to get your agents routing through a gateway today, without a procurement conversation or IT ticket.
- AI Gateway with multi-model routing and auto-failover
- MCP Gateway — connect agents to tools securely
- Your own token usage and cost logs
- OpenAI-compatible API — works with your existing code
Agent Router Enterprise
FOR LEADERS MANAGING AI
Everything in Service, plus the visibility, attribution, and guardrails an engineering leader needs to run AI across multiple teams without losing track of what it costs or how it behaves.
- Cross-team cost attribution, showback, and chargeback
- Admin controls — model and MCP access profiles by team
- Runtime AI Guardrails — PII redaction and policy enforcement
- Enterprise SSO — every request carries authenticated identity
- Distributed deployment — cloud, on-prem, edge, or per-region
Need More Help?
Work with Tetrate forward-deployed engineers to design safe agent operations