Building highly available (HA) and resilient microservices using Istio Service Mesh
What is High Availability in microservices
High availability systems are designed to provide continuous and uninterrupted service to the end customer by using redundant software performing similar functions. In highly available microservices, all the hosts must point to the same storage. So, in case of failure of one host, the workload in one host can failover to another host without downtime. The redundant software can be installed in another virtual machine (VM), or Kubernetes clusters in multicloud or hybrid cloud.
In this blog we will talk about how Tetrate helps platform architects to configure Istio service mesh for enabling automatic failover, achieving high availability.
Why do IT organizations need high availability in microservices?
Organizations today follow service-oriented architecture approaches, using microservices architectures to build distributed systems that span multiple workloads or multiple clouds. One of the main challenges of microservices is the way services communicate over the network using the API.
Communication between these services in a distributed system can fail due to many reasons, which include:
- Unreliable network
- High latency / slow speed
- Limited bandwidth
- Insecure network
- Changing topology
- Internal and external security threats
- High transport costs
- Heterogeneous network
Read the fallacies of distributed computing to see a list of assumptions an architect must consider to mitigate service outages in distributed systems.
For the above reasons, public clouds have failed multiple times. Public clouds like AWS, Azure, and Google Cloud provide a service level agreement (SLA) commitment of 99.99% uptime – that is, just under one hour of downtime a year. downtime with just 52.6 minutes/year).
When they fail to meet SLAs, cloud providers offer service credits, but this does not prevent their customers, and consumers, from getting frustrated when their transactions cannot be completed, or when they’re unable to access applications, leading to a loss of business.
AWS, the leading public cloud player, recently experienced multiple cloud failures. Users were locked out of messaging platforms, gaming applications, and social media sites. The AWS east region outage in 2021 brought down Disney+, Netflix, and many other services. Misconfigurations to routers brought down Whatsapp, Instagram, and Facebook globally in 2021. There have been many other outages.
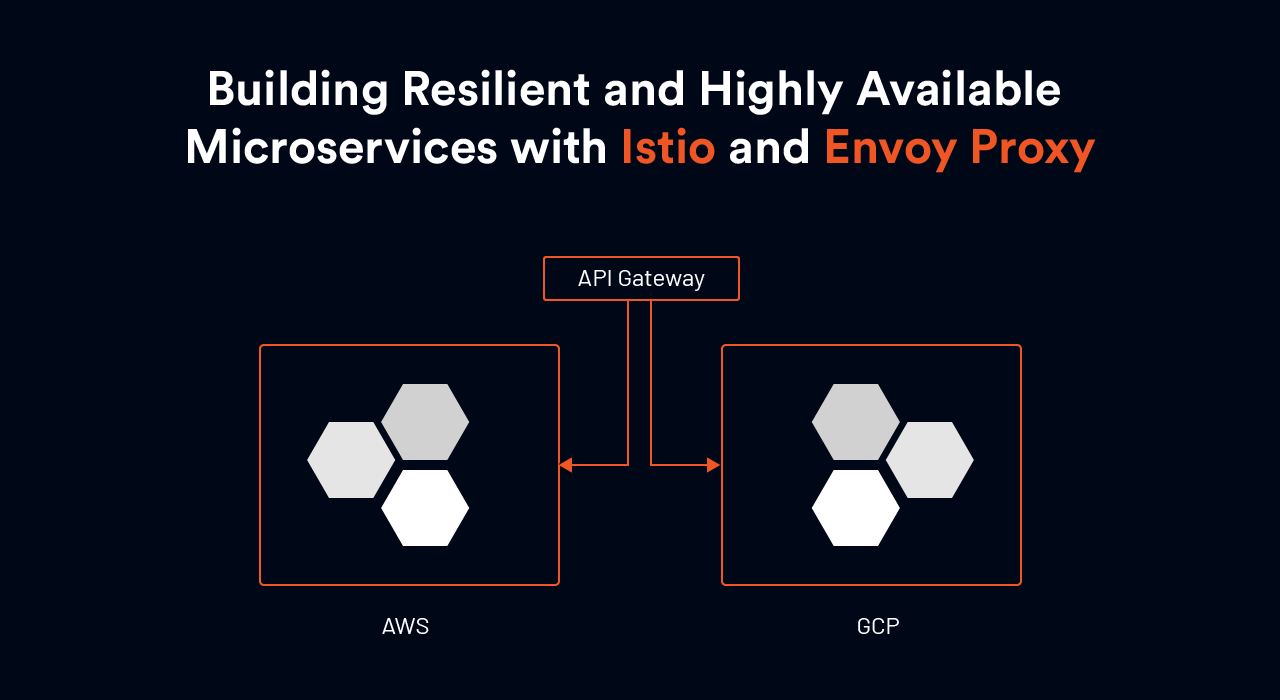
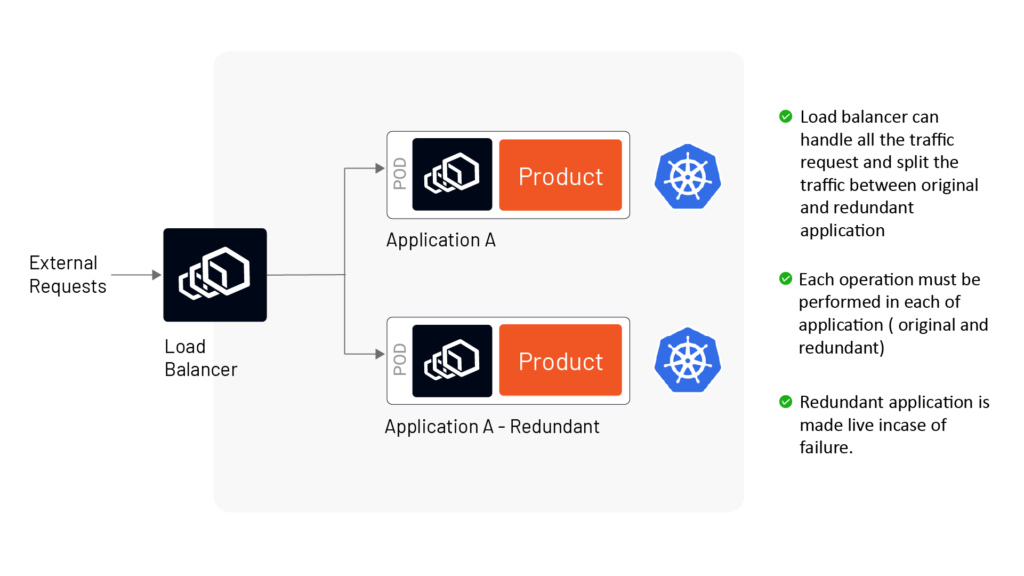
From an infrastructure perspective, a platform architect or enterprise architect should engineer a highly reliable and available system with redundant microservices using service mesh, which is a communication and security services layer in your microservice setup. The idea is that each service will have a proxy service ( often implemented using Envoy as the proxy software), and all the traffic requests and replies to and from each service will go through the Envoy proxy.
If you are new to Envoy Proxy, learn what Envoy is in 5 minutes. Or, if you are interested, you can learn why Envoy-based service mesh is an integral part of cloud native applications.
In the image below (Figure A), the Envoy proxy is used both as the load balancer and the sidecar proxy service to two services ( Application A and B). In case of failure, the service mesh can be configured to automatically redirect requests to the redundant instance of the microservice.
Four steps to achieve fault-tolerant and highly available microservices using a service mesh
If you are designing a microservices application, then high availability can be achieved in 4 logical steps:
- Create redundant hosts in multi-region or multi-cloud using a service mesh
- Ensure constant monitoring of traffic in the service mesh, with detection of site failures
- Plan for automatic multisite failover of the application
- Restart/Debug the lost host with minimal effort
Create redundant hosts in multiple regions and clouds using a service mesh
Platform architects consider various business and IT parameters before developing highly available and fault-tolerant systems. Some of the parameters which a platform architect would typically consider while planning different HA models are the geographic location of the business, partners, and customers; latency requirements to serve customers; the cost of service; the criticality of service; criteria for Disaster Recovery (DR), organizational policies; and industry regulations.
The resulting HA models can be classified broadly into four major classes, sequenced in order of complexity:
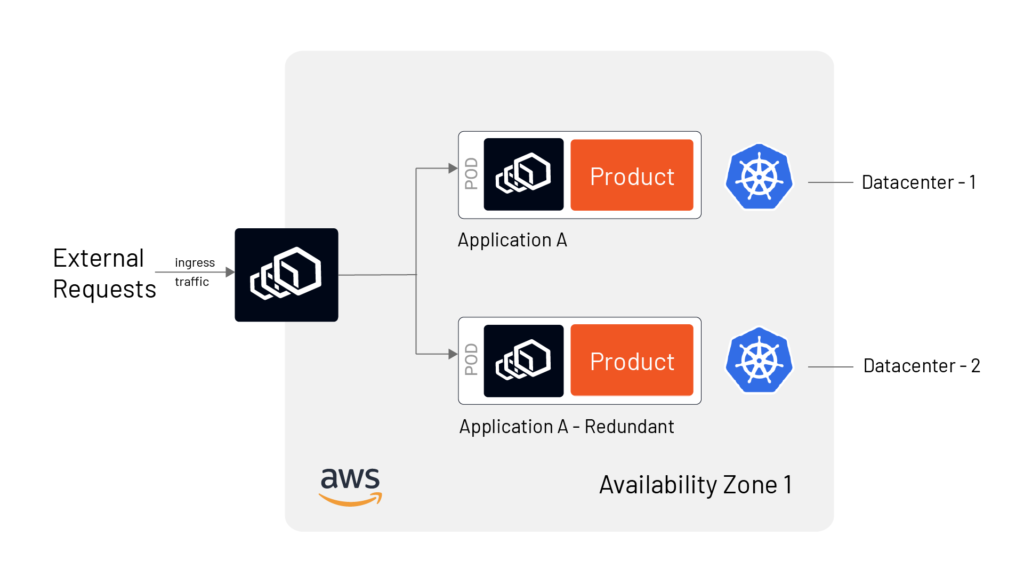
- High availability in a single availability zone (AZ) (can be single or multiple data centers
- High availability in multiple AZs in a single region
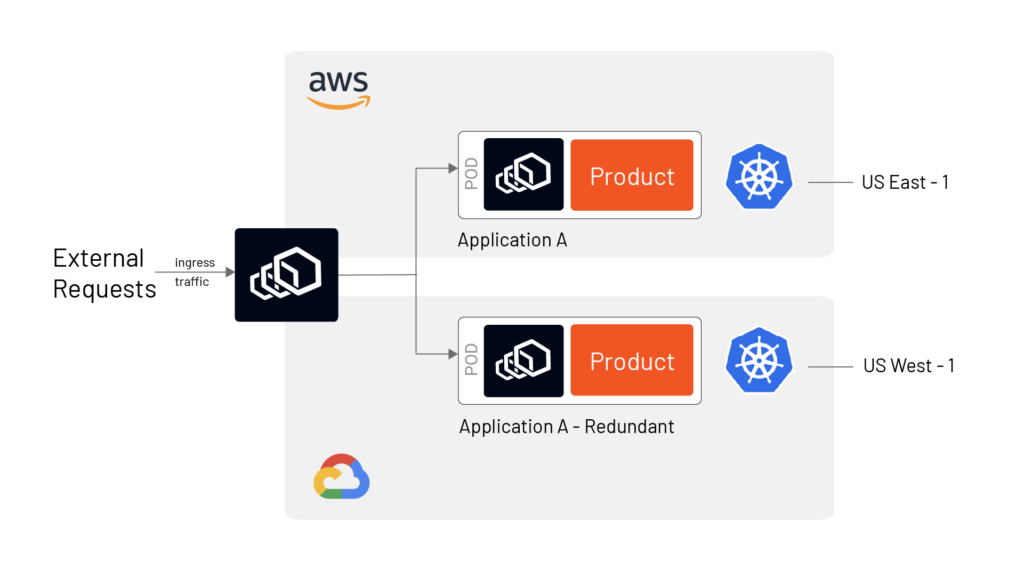
- High availability in multiple regions of the same cloud
- High availability in multiple regions in multiple clouds
While the class-1 HA in a single AZ ( refer to Fig B) is fairly simple to achieve, it may not be the best HA design. HA in multiple Availability Zone in multiple regions of multi-cloud (refer Fig C) provides a resilient and fault-tolerant service and allows organizations to avoid cloud vendor lock-in. However, in a multi-cloud environment, several other challenges can arise, such as different security postures, app portability, and interoperability.
The good news is platform architects can build a service mesh to achieve fault tolerance and high availability for their microservices using Istio.
Implementing High Available microservice with Istio
Istio service mesh provides infrastructure for service-to-service communication, which enables platform architects to abstract the networking layer from the core business logic of microservices. The application then includes both individual services and the service mesh connecting them.
With this architecture, architects and operators can:
- Easily manage east-west traffic ( between services inside a data center) and north-south traffic ( traffic between data centers)
- Achieve high availability and fault tolerance
- Maintain secure communication
- Deploy apps safely
- Gain visibility into internal and external traffic
Under the hood, Istio uses sidecar proxies, in the form of the Envoy proxy. All traffic is directed to a proxy, which then follows various traffic rules and security policies.
Figures B and C show an HA architecture in a single AZ and in multiple clouds, respectively, using service mesh.
How to implement high available microservice using Tetrate Service Bridge (TSB)
A microservices architecture based on service mesh can be used not only to achieve redundancy across two or more zones, enabling a smooth response to zone outages. Istio provides a mechanism to control the service mesh with granular network management functionalities, which is helpful to control inter-cluster and intra-cluster communication. While Istio is free and open-source, there can be a bit of a learning curve involved in implementing it.
Tetrate offers Tetrate Istio Subscription (TIS), an open-source distribution of Istio that is tested against all major cloud providers. Sign up for a subscription to experience life-cycle management benefits such as upgrades, maintenance, compliance, and functionality improvements. TIS also offers a Federal Information Processing Standards(FIPS)-compliant variant and is designed to run on any workload: VMs, Kubernetes, on-premises servers, and bare metal. Read more about Tetrate Istio Subscription and support from Istio experts here.
While you can run a service mesh using Istio, it’s challenging. To make things easier, and to add management capabilities, consider Tetrate Service Bridge(TSB), offered exclusively by Tetrate. (Unlike Istio, TSB is not open source.)
TSB enables security, agility, and observability for all edge-to-workload applications and APIs via one centralized, cloud-agnostic platform. It provides a management plane for built-in security and centralized visibility and governance across all environments for platform owners, yet empowers developers to make local decisions for their applications.
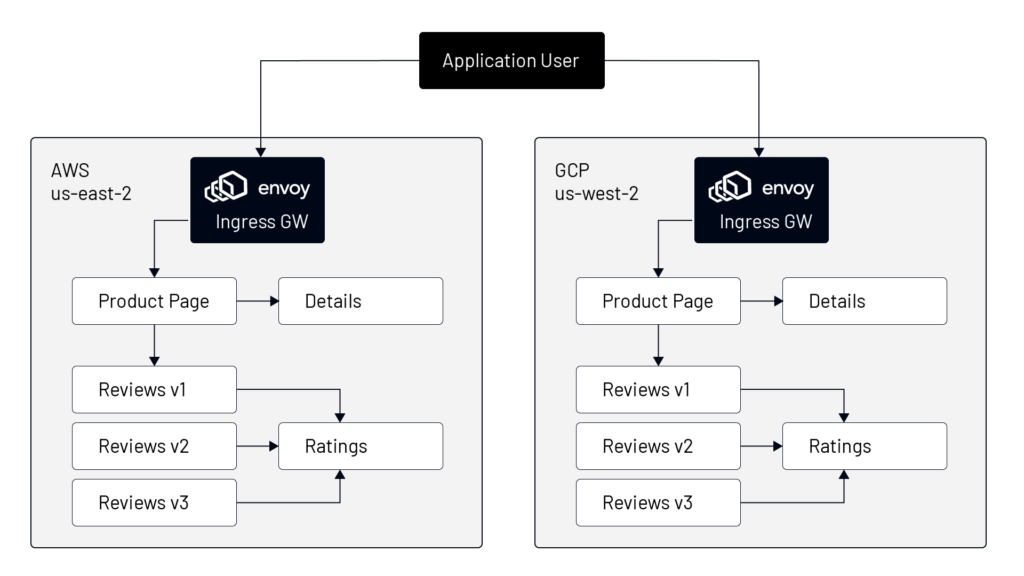
Now let us look at a brief example of TSB helping platform architects achieve fault-tolerant HA systems. We will start with a sample application called the bookinfo app (refer to Figure D), where the application gateway takes the traffic and sends it to the UI of the bookinfo app, i.e., “Product Page” service. The “Product Page” is dependent on two other services called “Details” and “Reviews”. “Reviews” application has three versions ( V1, V2, V3) deployed in the namespace for the purpose of canary testing. And each of the “Reviews” versions talks to the “Ratings” service to fetch the ratings of the products.
Platform architects can use Envoy proxies to implement API gateway capability for receiving traffic from external sources to each of the hosts in AWS and GCP. Envoy proxies should be used as a sidecar to each service to receive traffic from upstream services. Of course, apart from Envoy implementation, all other key features like load balancing, service-to-service authentication, and mTLS-based communication can be accomplished using Tetrate Service Bridge (TSB).
If you are interested in securing the communication in microservices, please read how to enable a Zero trust network for microservice using TSB.
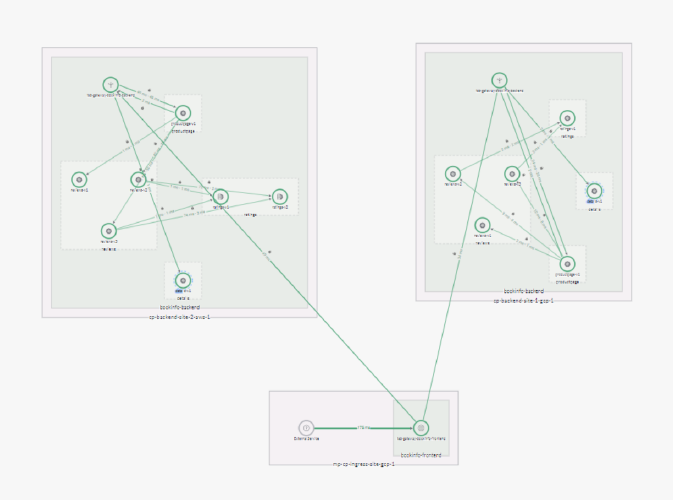
Once the “Product Page” application is configured, then the application topology in TSB would look something like the below:
Now, once you set up a redundant system in any region or any cloud, the next plan for the architect will be to achieve automatic failover to the redundant system in case of failure. And this can be achieved by constant monitoring and automatic failover to redundant systems.
Monitoring of highly available microservices using TSB
Once you install the Istio service mesh using TSB, the traffic between services is controlled and mediated by proxies and API gateways. Proxies will be responsible for incoming traffic and outgoing traffic, and all the network and security policies can be defined in the TSB management plane. With network communication within the service mesh growing in size and complexity, it is very important for application developers and infrastructure teams to constantly analyze the performance and quality of services every second, because a networks can fail at any time.
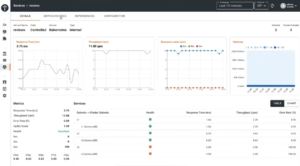
TSB offers a wide variety of metrics to monitor each service (refer to the image below). You get to learn about the behavior of each service based on traffic metrics such as response time, throughput, response codes, health, etc.
Instead of adding multiple tools to your analytics and monitoring stack, you can use the TSB management plane to observe the system behavior and distributed traces. In case of a problem in communication, TSB will automatically notify all the stakeholders about the network failure.
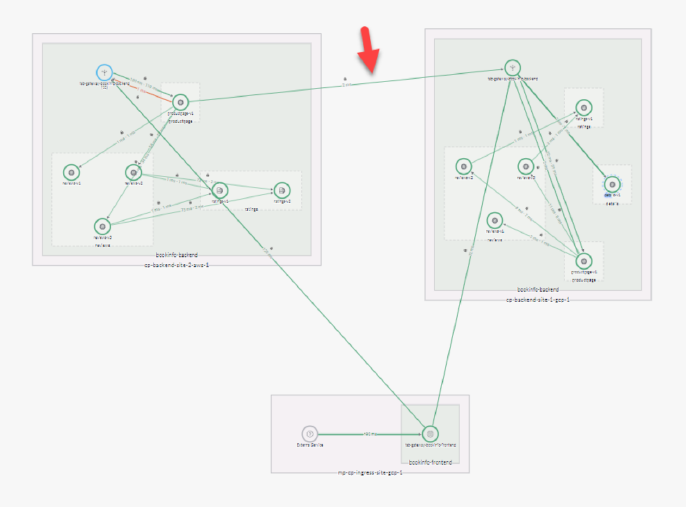
Initiate multicloud and inter-cluster failover using TSB
TSB allows automatic failover to redundant instances quickly in case of any issue in the traffic. TSB supports switching traffic in all scenarios of the HA system – multi-cloud, inter-region, or inter-cluster ( refer to Fig F).
First of all, TSB offers a management plane to configure applications replicated in multiple locations. The globally managed service mesh instances in each cluster ensure application resiliency by routing requests locally (in this case, within the AWS cloud). In case a local service is down -say the product page service of a bookinfo app is down – TSB allows routing of the traffic to remote clusters. In a nutshell, TSB re-routes all the traffic from the original app (refer to the image below) to the API gateway of the redundant cluster in GCP. The best part is TSB can handle inter-cluster and intra-cluster failover across clouds, which means it can perform multisite failover for all the four major classes of HA architecture.
Apart from failover to redundant sites, TSB also ensures resiliency in the application by allowing architects to easily configure network strategies like timeout, retry, and circuit breaking. TSB also allows platform architects to test the recovery capacity of the application in case of errors. For instance, you can intentionally inject faults like communication delays in the run-time and observe the variation in network latency. Or you can inject crash failures like HTTP error codes and check the response of the application. This testing will help architects to design the right traffic shifting rules.
TSB not only automatically handles the failover but also provides topology of the latest traffic routes, after failover to new clusters, through the UI.
With TSB, the app team, infra team, SRE team gets more granular, hands-on control with the centrally managed configuration and observability offered by the enterprise service mesh. Now let us see how the team can diagnose a failed case quickly using topology and service dependency graphs provided by TSB.
If you want to know more, then read a detailed blog on multisite failover using TSB.
Debug failed microservices using TSB
Debugging microservices applications is not as easy as monoliths. In monoliths, one can use breakpoints, or tweak environment variables and debug. However, to debug a microservice, the team needs four important things:
- Ability to trace logs and error codes at ingress gateways that are responsible for fetching traffic into a cluster
- Understanding as to how services are dependent on each other in a cluster
- The ability to examine configuration or YAML files of Istio resources (such as gateways and virtual resources) in each namespace across Kubernetes clusters
- The ability to check if the secrets responsible for mTLS connections are loading properly.
There are various ways to debug a service mesh, like using the istioctl analyze command on each istio resource and istioctl priory-config to check secrets are loaded properly in the gateways in the namespace. But these methods of using CLI are time-consuming.
TSB offers a management plane to find all the distributed traces and inspect Envoy access logs, which will be used to understand the traffic flow between the services in a cluster. This will help the infra team to debug if there are certain problems in traffic and why traffic is being rejected by API gateways.
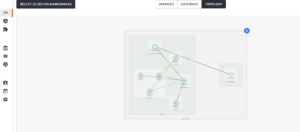
Secondly, TSB offers dependency graphs that will help teams to understand the upstream and downstream services or shared volumes across services that are getting impacted or impacting a service uptime. In the image below, the dependencies on the impacted service, product page, are represented by a graph that shows the various other dependent services and namespaces in the same K8S cluster. Thus, the infrastructure team can narrow down their investigation to a limited number of services in the whole cluster.
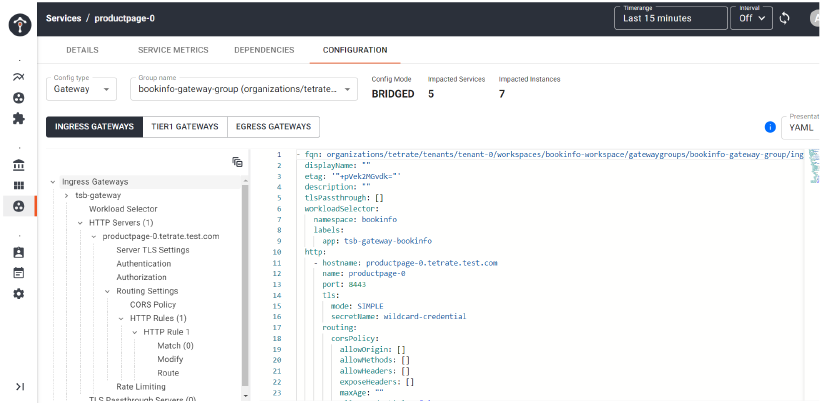
Finally, TSB helps in checking the configuration of service mesh resources in a single plane, and fixing it in case that’s required. Under the configuration tab (refer to the screenshot below), the application team or infrastructure team can quickly check all the configuration YAML files ( for gateway, traffic, and security) applicable to a service (such as product page).
Conclusion
As organizations rely more and more on cloud and network-based applications, it is vital to make their applications available and reliable as much as possible. Whatever approach they use to configure their HA applications, Istio service mesh can be used as a layer between application logic and infrastructure and to automatically perform failover. And Tetrate Service Bridge makes implementing and managing the process much easier.
With HA, end users remain connected to the application servers when the active product system fails. User sessions that are actively accessing the application during an outage pause for a few seconds until the new redundant system, configured in some other cloud/region/cluster, becomes available again after completion of failover.
So contact us to see how we can help.










