
Compliance Mandate
"CISO Needs Proof PII Is Protected."
Agents send user data to models. Teams need proof sensitive data is blocked before reaching providers.
Agents send user data to models. Teams need proof sensitive data is blocked before reaching providers.
Misbehaving agents need to be stopped instantly — without redeploys or shutting down the system.
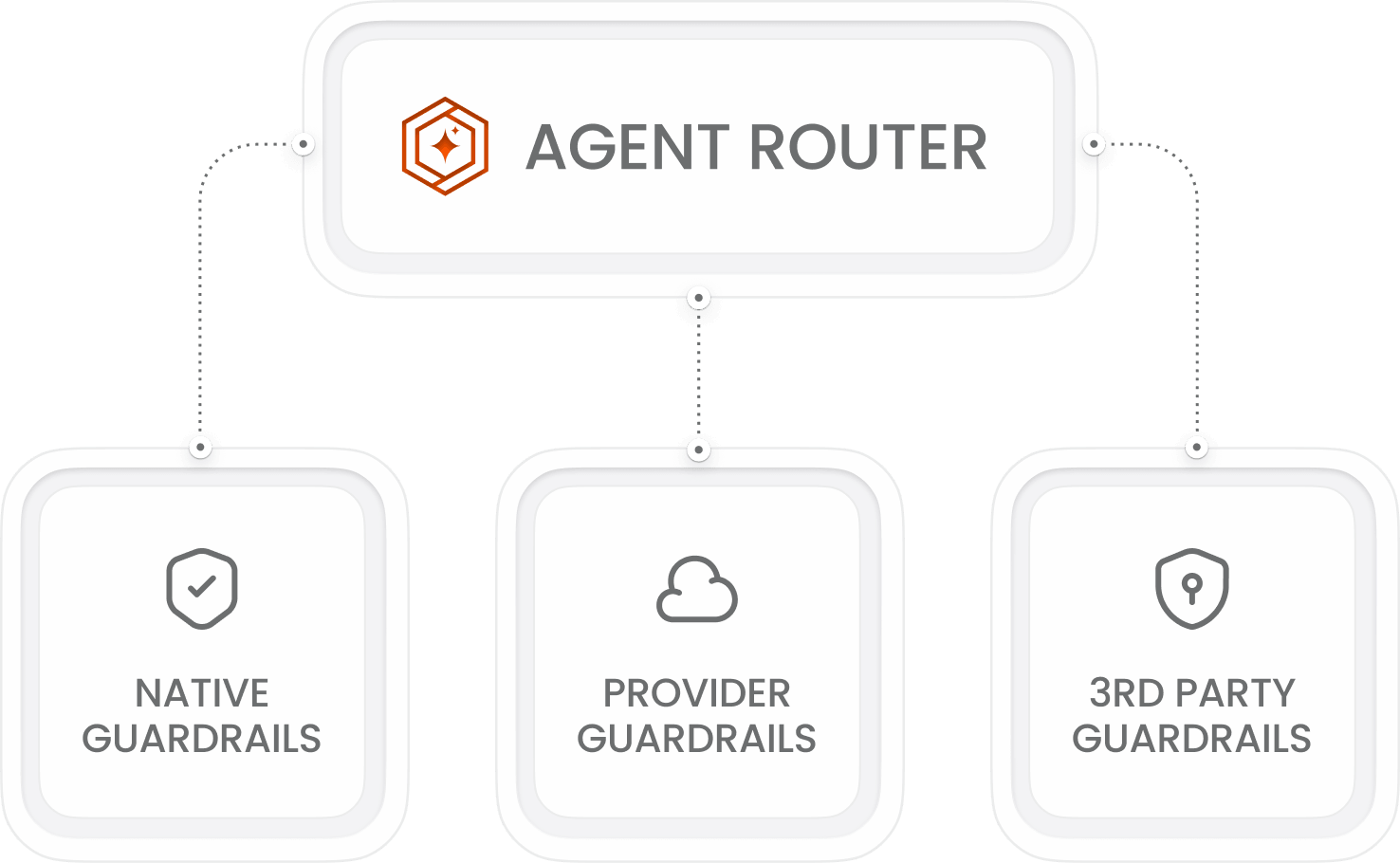
Connect existing guardrails and inspection tools into the request flow — without replacing your current stack.
AI Guardrails scans requests for sensitive data — SSNs, cards, emails, phone numbers, health data, or custom patterns. Matched data is redacted before forwarding, so providers only receive clean input. Original data never leaves the gateway.
Rules filter prompts before they reach the agent and review responses before they return. They help block prompt injection, unsafe outputs, and policy violations before the agent acts.
Integrate providers like Lakera Guard, Protect AI, or custom inspection services directly into the Agent Router pipeline, so every agent follows the same security flow.
Rules-based guardrails match deterministic patterns — a regex for an SSN, a denylist of banned words, a check that a tool is in an agent's allowed list. They're fast (single-digit ms), predictable, and easy to audit. The tradeoff: they only catch what you anticipated.
Semantic guardrails use a small classifier or LLM to evaluate intent rather than surface patterns — "does this look like a prompt injection attempt" rather than "does this match this regex." They catch the variations rules miss, but they're slower (hundreds of ms), probabilistic, and harder to audit ("the classifier returned 0.84" vs. "rule X matched").
In production the two are layered. Rules handle the well-defined cases cheaply; semantic checks handle the fuzzy ones where intent matters more than pattern. Agent Router runs both inline in the same filter pipeline and logs which type fired for every decision.
Recall and precision pull against each other. Lower the threshold and you catch more violations but block more legitimate traffic; raise it and false positives drop but real violations slip through. The right balance depends on which error costs you more.
Three moves that help:
The audit log captures the classifier score on every decision, so you can review near-misses on both sides and refine over time.
The request path is the sequence of operations between your agent sending a request and the provider receiving it. When a guardrail runs "in the request path," it executes inline — as part of that sequence — rather than asynchronously after the fact.
The difference matters because a guardrail in the request path can block a request before the provider sees it. A guardrail running after the fact can only report what already happened. Inline enforcement is the only kind that actually prevents data exposure or stops a violation; everything else is just logging.
AI Guardrails is an engineering layer, not a security platform. It's owned and configured by platform engineering, and it produces outputs — audit logs, enforcement records, a documented control point — that your security team can use.
The typical motion: engineering adopts Agent Router for routing and cost visibility, then turns on AI Guardrails when compliance and security start asking questions. Your CISO is a beneficiary, not the buyer.
AI governance is the organizational discipline — policies, risk frameworks, approval processes, compliance programs. It defines what your org's rules should be.
AI Guardrails is the runtime mechanism that enforces those rules in the request path. When a guardrail blocks a request with PII, redacts a response, or stops a misbehaving agent, that's enforcement happening inline — at the moment the agent makes a call, not after the fact.
You need both. Governance decides the policy; AI Guardrails is the enforcement primitive that makes runtime policy actually run.
AI Guardrails is designed to complement existing security tooling, not replace it. You can integrate your existing guardrail provider — Lakera Guard, Protect AI, or a custom content inspection service — as a pluggable filter step in the Agent Router pipeline.
Your security team keeps their tool. The gateway wires it into the request path so every agent benefits from it, with results logged alongside native guardrail decisions in the same attribution record.
Native guardrail rules — PII detection, prompt filtering, access controls — run in the Envoy filter chain and typically add 1–5ms per request. That's negligible relative to LLM inference, which is measured in hundreds of milliseconds to seconds.
External guardrail provider calls (like Lakera or Protect AI) add more latency depending on the provider's response time, with configurable timeouts. Every request's actual overhead is captured in the latency_added field so you can measure it precisely rather than guess.
AI Gateway access controls are structural — they govern who is allowed to call what. Which teams can use which models, which agents can reach which MCP tools, what budget limits apply. These are included in all Agent Router editions, including the free tier.
AI Guardrails is content-level enforcement — it governs what's inside the requests and responses, regardless of who sent them. A team might be permitted to call Anthropic (an access control decision), but their requests still pass through PII detection and prompt filtering (guardrails) before reaching the provider.
The two layers run in sequence in the same pipeline and complement each other.







