Routing
Route by model, team, token threshold, or request metadata in combination.

Production-grade circuit breaking, weighted routing, and native OpenTelemetry for your LLM gateway. Change one line of code to get started.

Based on Envoy
Built on Envoy AI Gateway, co-created and maintained by Tetrate with Bloomberg. See published performance benchmarks for MCP overhead, control-plane scaling, and methodology.
Every request your agents make passes through the same six-stage pipeline inside AI Gateway. Each stage runs in order and can short-circuit — returning a response directly — or pass to the next. The pipeline runs in the Envoy filter chain: each stage adds microseconds, not milliseconds. This is what teams mean by an LLM gateway — a single control point between your agents and model providers.
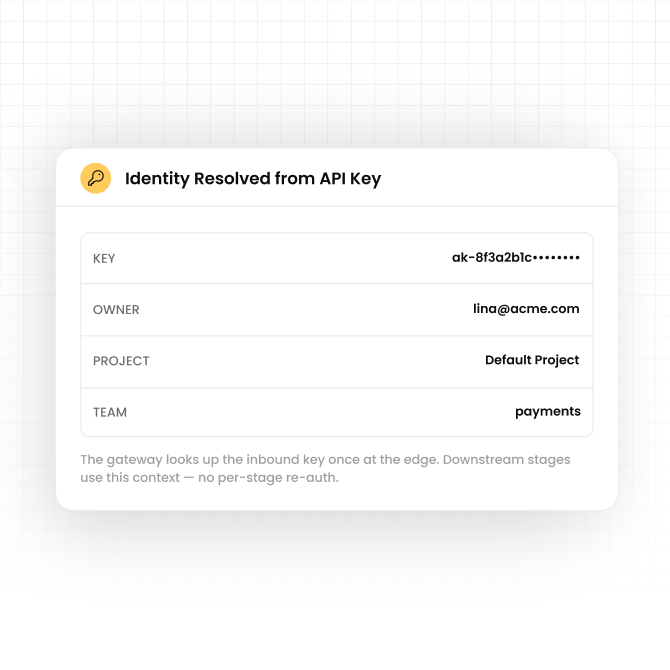
Look up the inbound API key to resolve owner, project, and team. All downstream stages use this context for quota checks, routing, and log attribution.
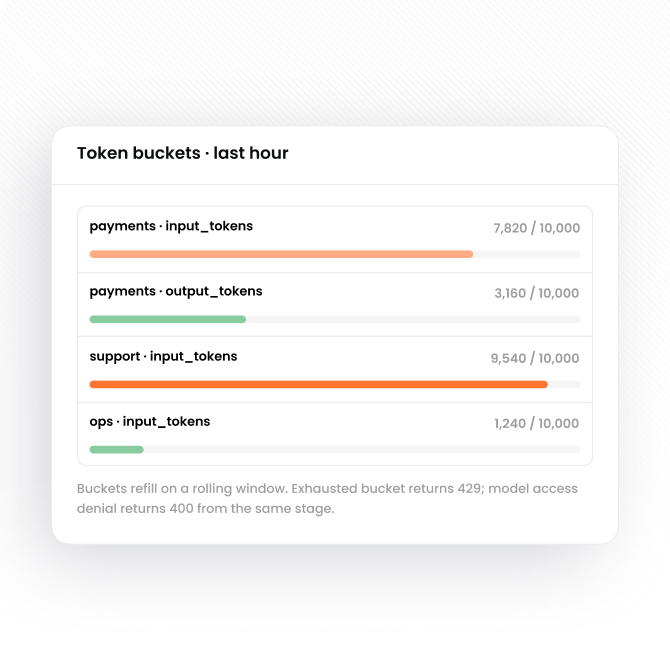
Verify the team's access profile permits the requested model. Token- window rate limits run here — buckets configured per tenant decrement from the token counts the gateway filter emits.
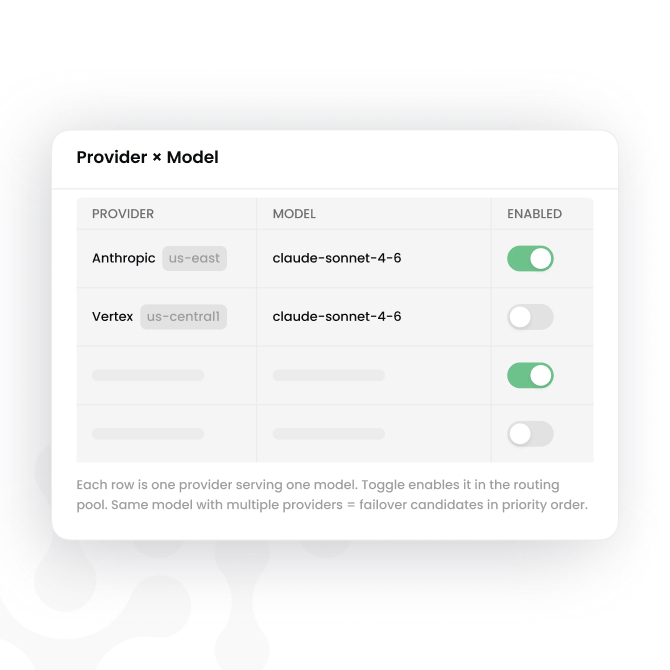
Pick the provider that serves the requested model. Al Gateway extracts the model from the request, matches an AlGatewayRoute rule, and selects a backend — Anthropic, Bedrock, Vertex, OpenAl, Azure, your BYOK credentials, or self-hosted. Same model can route to multiple providers.
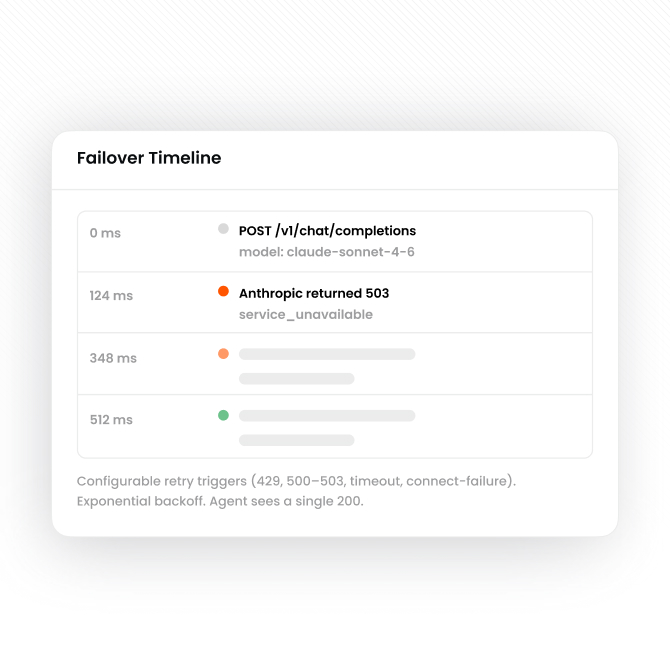
Send to the selected provider. On retry-eligible failures — configurable status codes (e.g. 429, 500-503), connect failures, timeouts — Envoy retries with exponential backoff, then shifts to the next-priority provider in the rule. Agent sees a successful response.
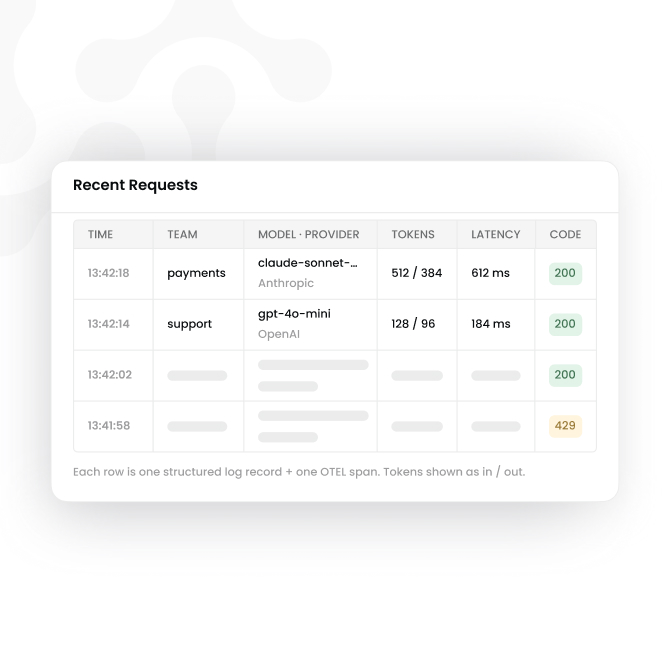
Write a structured access log and an OpenTelemetry trace span. Captures team, agent, model, provider, token counts, latency, retry count, and status — feeds spend rollups, dashboards, and your configured sink without touching agent code.
Route by model, team, token threshold, or request metadata in combination.
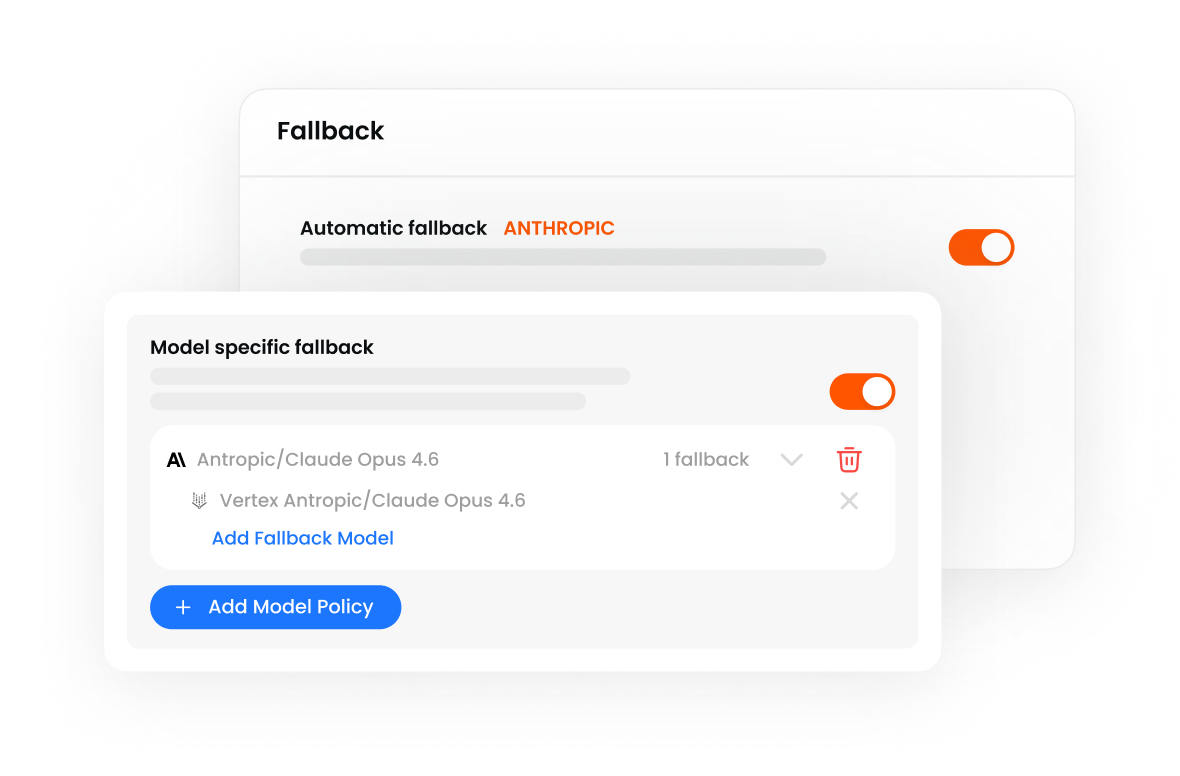
Automatic recovery from provider failures.
Every request produces a structured log record written to your configured sink.
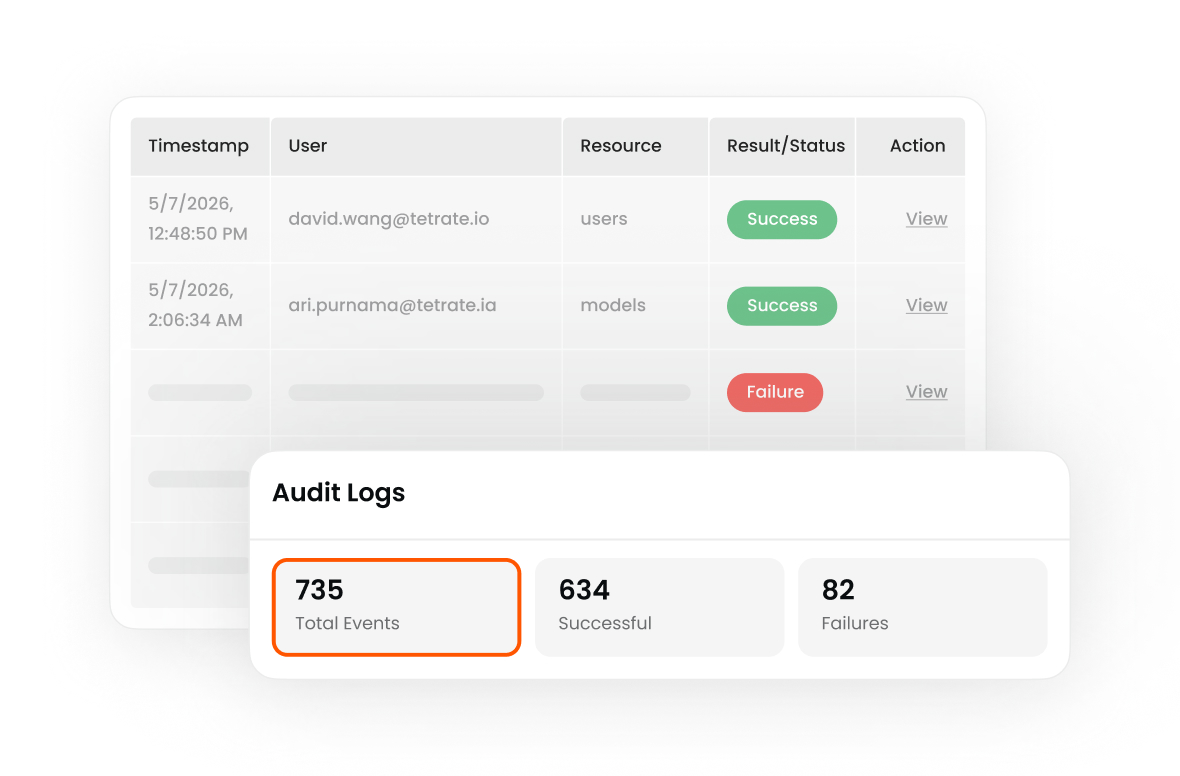
Enforce spend limits before requests hit the provider.
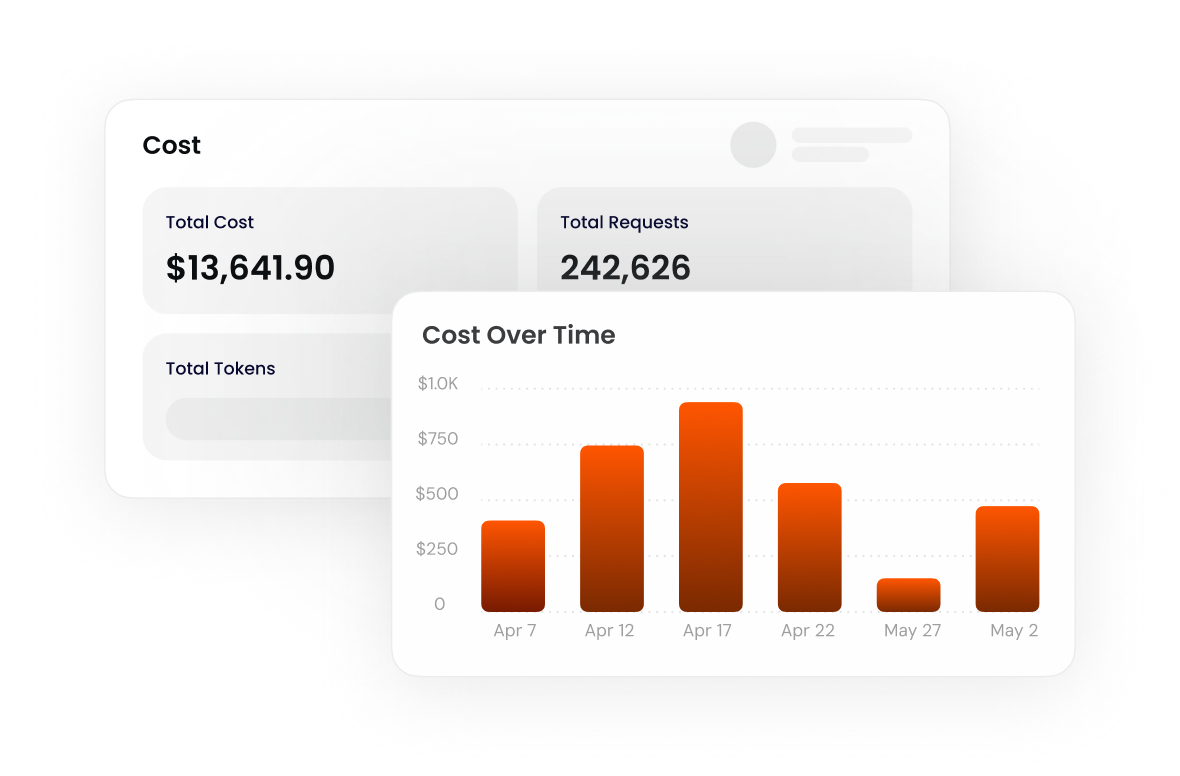
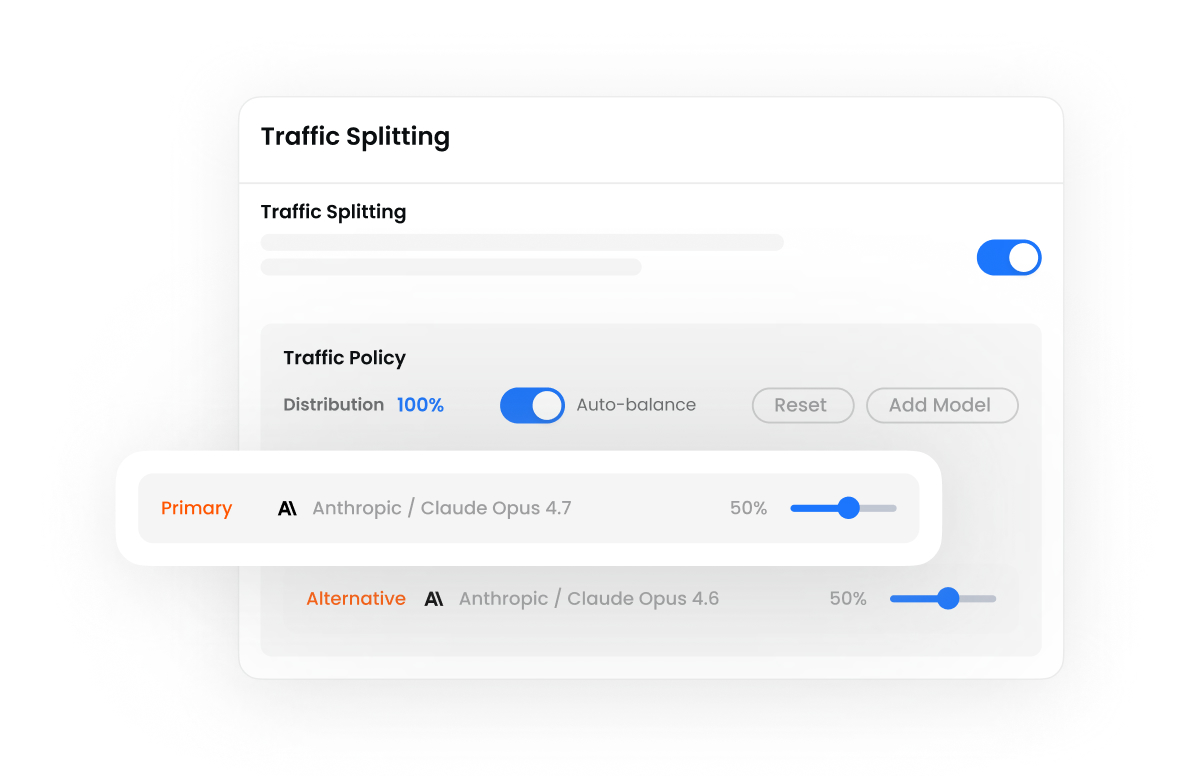
Distribute traffic across multiple models.
Tetrate Agent Router is provider-neutral, framework-agnostic, and
OpenAI-compatible.
It doesn't replace your stack, it sits in front
of it.




















Evaluating AI gateways? Start with our evidence-based comparison hub, then drill into head-to-head guides.